About
2017 - Trained a GoogLeNet (Inception v1) CNN on ImageNet from scratch using a 4-GPU machine we built in-house at Eurecat. Had to code the gradients of a custom self-supervised loss in Caffe.
2018 - Wrote blog posts with intuitive explanations of Cross Entropy Loss and Ranking Loss that got cited in reference tutorials and still get ~10k views/month.
2019 - Attempted to develop CLIP before CLIP but missed because I used only one random element in the batch as negative instead of all.
2020 - Learned everything about video and huge computing clusters pushing the SoA of video action recognition at Huawei.
2021 - Learned everything about RecSys by creating an R&D framework from scratch at Shutterstock (and found that my latest PhD ECCV publication was actually a RecSys!)
2022 - Consolidated my RecSys (and A/B testing!) knowledge at Shutterstock by productionalizing 2 models, publishing at ACM RecSys and submitting 2 patents.
2023 - Generative time! Training text-to-image models from scratch with the huge Shutterstock catalog. 4 models deployed. 6 patents.
2025 - Principal Applied Scientist. Leading SSTK ML in the Generative Era.

Places you can find me besides in the mountains:
raulgombru@gmail.com
Github
Linkedin
Twitter
Experience
2021-Present Data Scientist - Computer Vision.
Shutterstock, Dublin. Generative, Computer Vision, RecSys.
2020-2021 Research Intern (PhD).
Huawei Ireland Research Center, Dublin. Working on video action recognition for human behaviour analysis.
2016-2020 Computer Vision Researcher
Eurecat Technology Centre, Barcelona. Worked on R&D computer vision consultancy projects and on the PhD research.
2016-2017 Research assistant
Computer Vision Centre, Barcelona. Working with Convolutional Neural Networks in image text understanding.
2015–2016 Research Intern (MS), EURECAT, Barcelona.
Internship in the context of the master thesis. Worked on text detection.
Education
2016–2020 PhD in Computer Vision
Eurecat and Computer Vision Center, Universitat Autónoma de Barcelona, Exellent Cum Laude.
- Research stay in University of Trento. Working with the Multimedia and Human Understanding Group.
- Internship in Huawei Ireland Research Center. Working in the human behaviour analysis group.
2015–2016 Master in Computer Vision
Oficial master at Universitat Autónoma de Barcelona. GPA – 8.45.
2010–2014 Bachelor’s Degree in Telecomunications Engineering
ETSETB, Universistat Politécnica de Catalunya, GPA – 6.8. Specialized in Audiovisual Systems
Computer Vision R&D
Image Retrieval
I’ve an extense experience training deep models for image retrieval, using triplet nets architectures and ranking losses with different deep learning frameworks.
- Image by text retrieval learning from Social Media data. [Project]
- Face images by attributes retrieval. [Project]
- Image retrieval by text and location. [Project]


Image Tagging and Classification
I’ve also designed and trained models for image tagging tasks (or Multi Label Classification) applied to different scenarios.


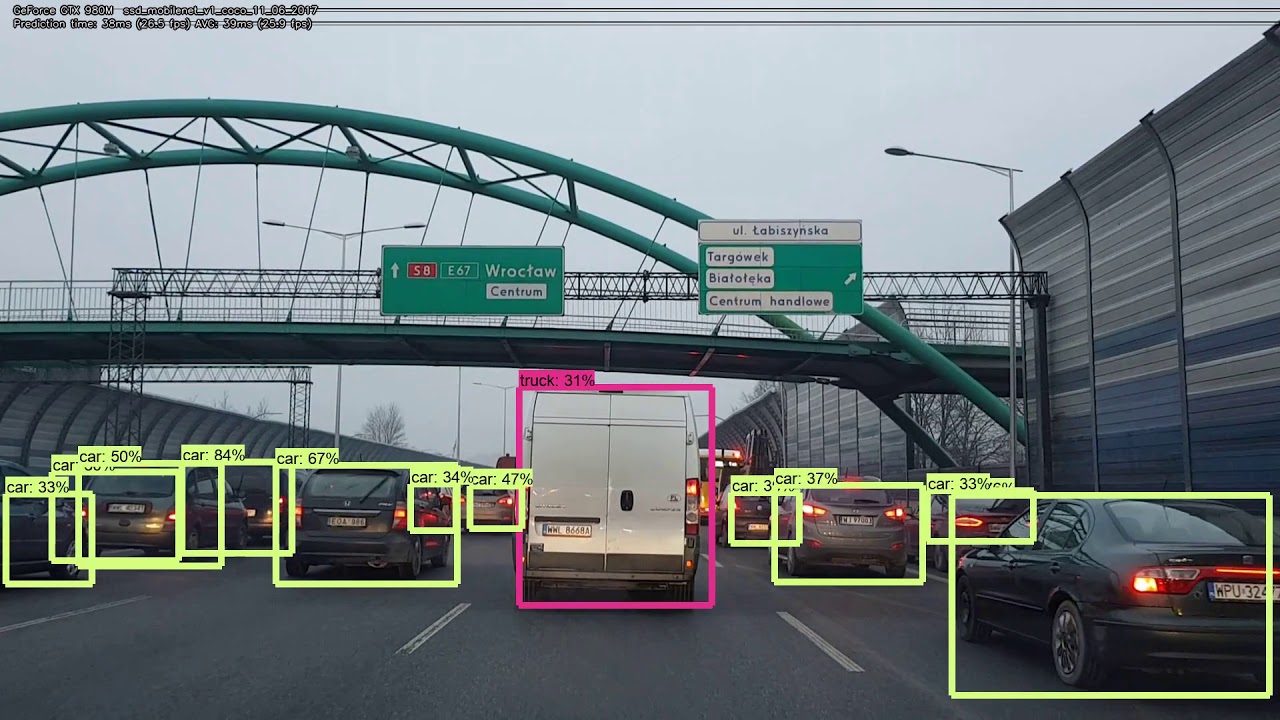
Object Detection
I’ve experience training object detection models (YOLO, Faster-RCNN, Mask-RCNN, etc) in different datasets.
- I designed a small CNN (based on MobileNet) to embed it in a parking camera for car detection.
- I trained Mask-RCNN (Detectron 2) for person detection ussing annotated video frames.

Object Segmentation
I’ve trained object segmentation models (FCN, Mask-RCNN) for different tasks.
- Face and hair segmentation model to embed in a Nvidia Jetson. [Project]
- Scene Text segmentation to detect text at a pixel level. [Project]
- Defects in sewers segmentation model for an automatic sewer inspection robot. [Project]


Text Detection
I’ve experience in scene text detection and have worked in several projects in the field.
- I organized the COCO-Text Detection Competition. [Project]
- I published a method to improve the former scene text detection pipeline. [Project]
- Selective Text Style transfer, a model which detects text in an image and then stylizes it. [Project]


Video Understanding
I’ve worked on video action recognition for human behaviour analysis, improving state of the art SlowFast models and training then on several large scale datasets.

NLP
I’ve also experience with NLP and have trained word representation models (Word2Vec, GLoVe, BERT) and LSTM networks for text understanding, most of the times working in multimodal (images and text) tasks.
- Training word representation models with Social Media data for an image by text retrieval task. [Project]
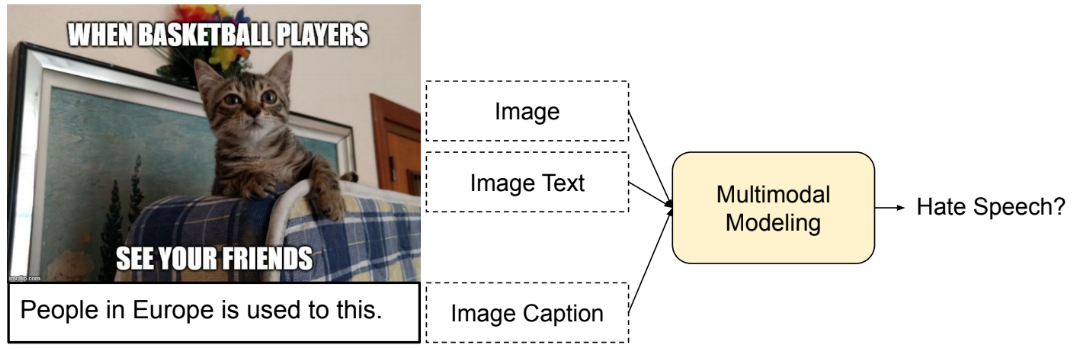
- Training an LSTM with Twitter data for multimodal hate speech classification. [Project]
Other Projects
Technical Courses Development
I’ve worked developing online technical courses to teach machine learning to computer scientist by doing applied projects.
External Writer
I’ve worked as a freelance technical writer and have recognized written communications skills, especially to explain technical concepts in an intuitive way.
- Neptune Blog Post: Implementing Content-Based Image Retrieval with Siamese Networks in PyTorch
SetaMind: Image Classification App
I developed this Android App that, given a photo of a mushroom, recognizes its species. It uses a CNN that runs locally in the phone.
Social Media Analysis
I developed tools that learn from images and associated text, and applied that to Instagram data analysis.
- I presented an application of this work to #Barcelona Instagram images and tourism in the TurisTICForum of Barcelona.
Blog
I have a blog where I explain my PhD work, toy experiments and general machine learning concepts. One of its articles explaining Cross-Entropy Loss is featured in the Deep Learning fast.ai course and in the deeplearning.ai Introduction to TensorFlow course. It’s visited by 15k people per month. I constantly receive good feedback aplauding my intuitive explanations.