What Do People Think about Barcelona?
In a former post, Learning to Learn from Web Data, we explain how to embed images and text in the same vectorial space with semantic structure. We compare the performance of different text embeddings, and we prove that Social Media data can be used to learn the mapping of both images and text to this common space.
Objective
This post aims to show that learning this common space from Social Media data has very useful applications. To do so, we will learn the embedding with Instagram posts associated to a specific topic: Barcelona. That is, images with captions where the word “Barcelona” appears. Once the embeddings are learnt, we will be able to infer what people talks about when they use the word “Barcelona”, or what images people relate with Barcelona and another topic. That can lead to social or commercial interesting analysis. For instance:
- What are the most common words that appear along with Barcelona?
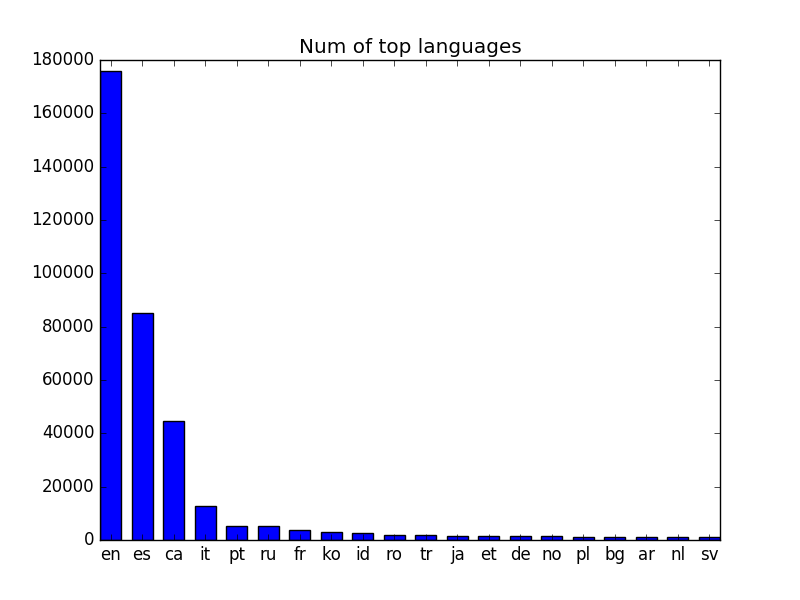
- What languages do people use most when they speak about Barcelona?
- What words do people write along with the word “food” and “Barcelona”?
- What kind of images do people post when they talk about “healthy” and “Barcelona”?
- What kind of images do people post when they talk about “beer” and “Barcelona”?
- What kind of images do people post when they talk about “cerveza” and “Barcelona”?
- What kind of images do people post when they talk about “healthy”, “restaurant” and “Barcelona”?
- What kind of images do people post when they talk about “gracia” and “Barcelona”?

Notice that this kind of analysis could be applied to any other concept instead of Barcelona if sufficient data can be collected.
The code used is available here.
For a more detailed explanation of the embeddings learnt, please refer here or here.
Data adquisition and filtering
Data adquisition
To download the images from Instagram I used InstaLooter, a simple python script that parses the Instagram web without the need API access (the instagram API is only available for approved apps). You can download images quite fast with that. I searched for the word “barcelona” and downloaded 623K images and captions.
Dataset filtering
-
Images without a caption or short caption (less than 3 words).
-
Images with captions in other languages than english, spanish or catalan. I used langdetect, a python language detection library ported from Google’s language-detection. I discarded posts that had 0 probabilities of belonging to one of those languages.
- Images from users contributing with a lot of images. To avoid spam accounts and single users to influence a lot in the embedding learning, I discarded images from users having more than 20 images.
- Images containing other cities names in their captions. This kind of images tend to be spam.
Discards -->
No captions: 2122
Short caption: 27241
Language: 37026
User: 161333
City: 70224
Number of original vs resulting elements: 325253 vs 623199
After the filtering, the dataset was divided in 80% train, 5% validation and 15% test sets.
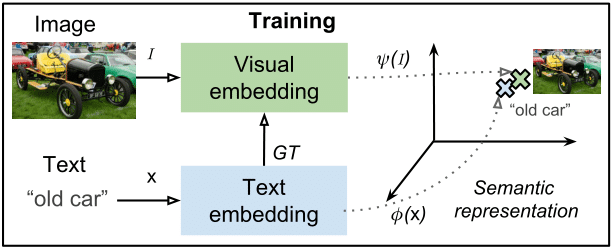
Learning the joint embedding
A Word2Vec representation for words is learned using all the text in the training dataset. Notice that a single Word2Vec model is learned for all languages. Then, a regression CNN is trained to map the images to the Word2Vec space. For a more detailed explanation of the embeddings learning, please refer here or here.
Word2Vec
Word2Vec learns vector representations from non annotated text, where words having similar semantics have similar representations. The learned space has a semantic structure, so we can operate over it (king + woman = queen). A Word2Vec model is trained from scratch using the Gensim Word2Vec implementation. A dimensionality of 300 is set for the embedding vectors. We used a window of 8 and do 50 corpus iterations. English, spanish and catalan stop words were removed. To get the embeddings of the captions, we compute the Word2Vec representation of every word and do the TF-IDF weighted mean over the words in the caption. That’s a common practice in order to give more importance in the enconding to more discriminative words. To build our TF-IDF mode, we also use the Gensim TF-IDF implementation.
Regression CNN
We train a CNN to regress captions Word2Vec embeddings from images. The trained net will let us project any image to the Word2Vec space. The CNN used is a GoogleNet and the framework Caffe. We train it using Sigmoid Cross Entropy Loss and initializing from the ImageNet trained model.
Textual analysis using Word2Vec
Word2Vec builds a vectorial space were words having similar semantics are mapped near. So a Word2Vec model trained on Instagram data associated with Barcelona, let’s us do an interesting analysis based solely on textual data.
Which words do people associate with “Barcelona” and “ “ :
Generic:
- food: thaifood foodtour eatingout todayfood foodislife smokedsalmon eat degustation foodforthesoul bodegongourmet
- shopping: shoppingtime shoppingday shopaholic onlineshopping multibrand musthave loveshoes emporioarmani casualwear fashionday
- beer: spanishbeer estella desperados beerlover aleandhop beers brewery estrellagalicia mahou goodbee
Beer:
- cerveza: cervezanegra cervezas jarra beertography birra beerlife fresquita birracultura birracooltura lovebeer
- cervesa: cervesaartesana yobebocraft beernerd idrinkcraft bcnbeer lambicus cerveses instabeer daus cervezaartesana
- estrella: spanishbeer cerveza lager damm cnil estrellagalicia estrellabeer cervecera gengibre fritos
- moritz: moritzbarcelona fabricamoritz beerstagram volldamm craftbeer damm beerxample lovebeer barradebar beerlovers
Restaurants:
- sushi + restaurant: sushibar sushitime japo gruponomo sashimi sushilovers japanesefood bestrestaurant sushiporn comidajaponesa
- healthy + restaurant: salad eathealthy delicious flaxkale veggiefood healthyfood cangambus healthyeating thegreenspot menjarsaludable
Neightbourhoods:
- sants: barridesants pisapis assajarhostot santsmontjuic inconformistes menueconomico poblesec menubarato santsmontjuc hostafrancs
- gracia: grcia viladegracia barridegracia barriodegracia farr jardinets grandegracia torrentdelolla hotelcasafuster lanena
- santantoni: santantoni descobreixbcn vermouthlovers modernism fembarri bcncoffee bcnmoltms vermouthtime mesqhotels larotonda
- badalona: pontdelpetroli badalonamola lovebadalona santadria badalonacity badalonaturisme escoladevela igbadalona bdn portviu
- sitges: igerssitges santperederibes sitgesbeach intadogs garraf gaysitges aiguadol imperfectsalon patinavela visitsitges
What atractions do people talk more about?
We can compare the top visited tourist attractions in Barcelona with its names appearence frequency.
Most frequent attractions mentioned on Instagram: gaudi, sagradafamilia, barceloneta, parkguell, campnou, tibidabo, sitges, montserrat, gracia, eixample, poblenou, gothic, casabatllo, larambla, raval, lapedrera
Most visited tourist attractions 2016:
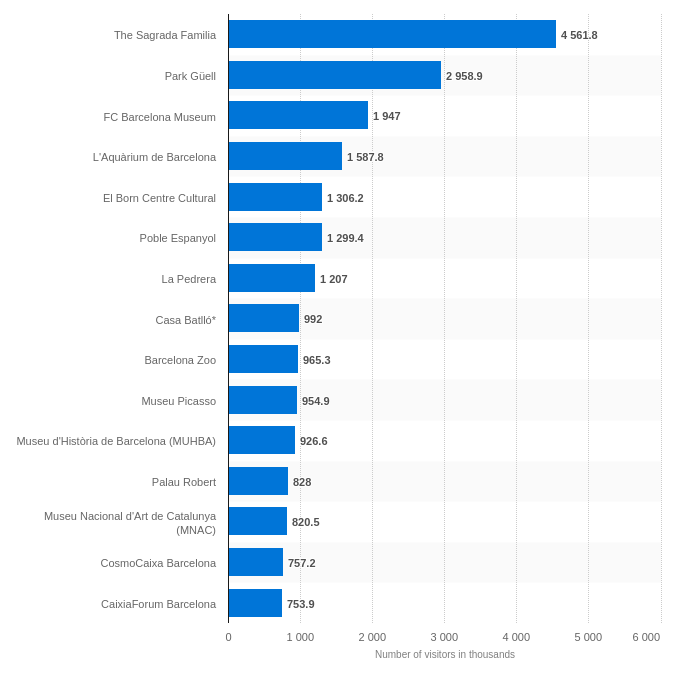
We can compare the top visited attractions with the most mentioned attractions, which we could see as the most trendy attractions. Because people maybe visits a lot the Museu Picasso but don’t talk about it in Social Media. A conclusion could be that people talk more about architecture and neighbourhoods than about museums, and that people also post a lot about places near Barcelona (Sitges, Montserrat…).
Top word in each language
Histograms of the top frequent words in each of the languages.
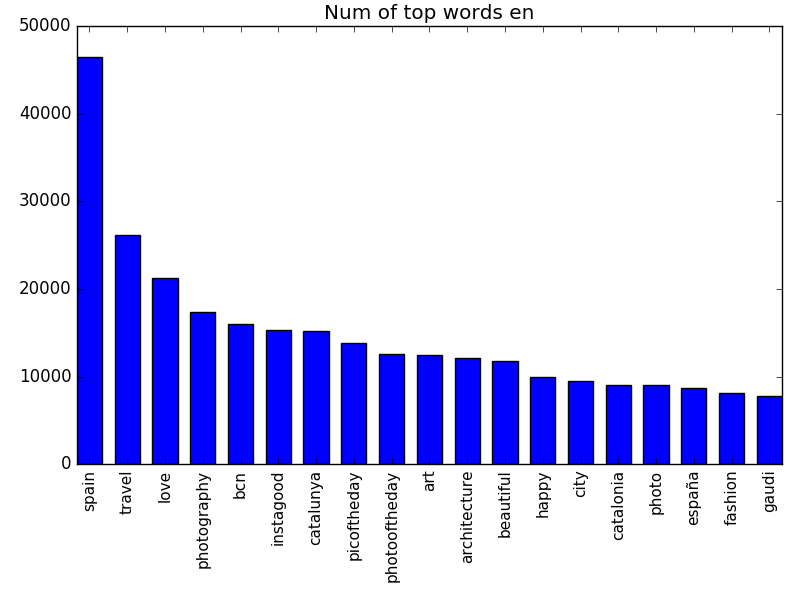
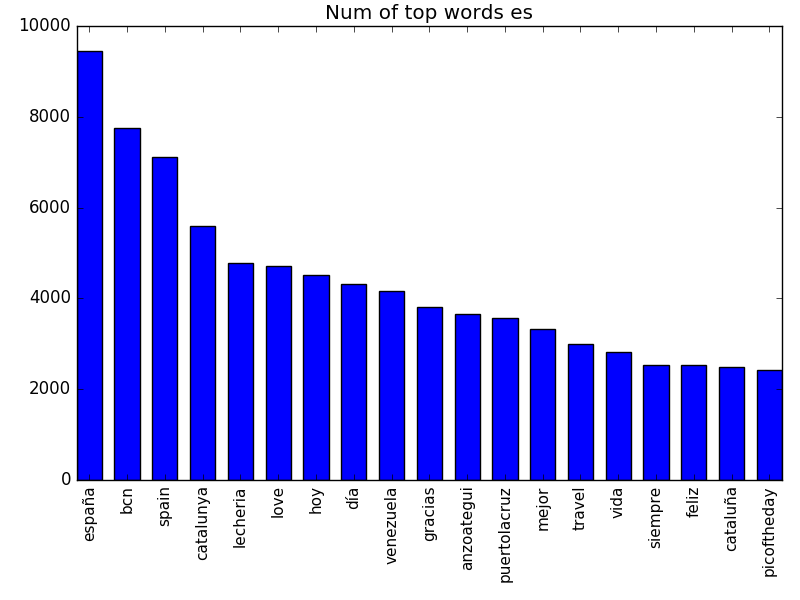
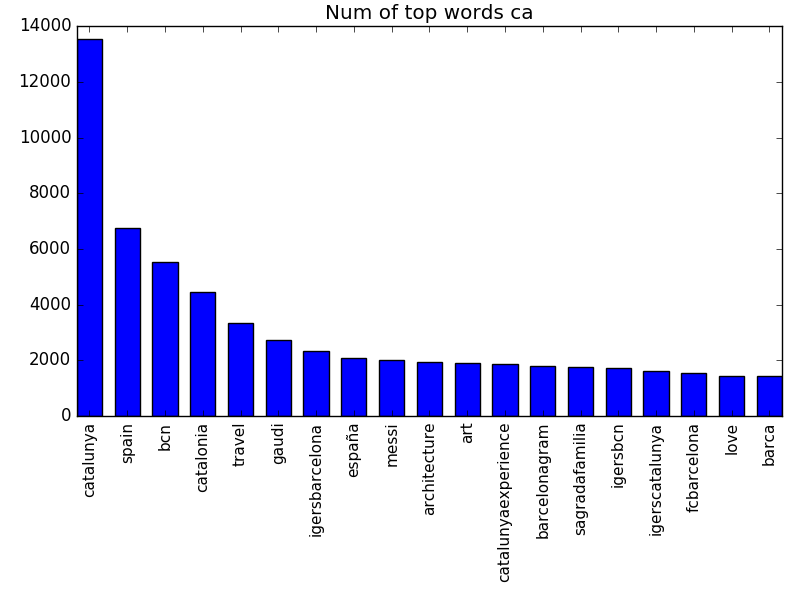
Images associated with text concepts
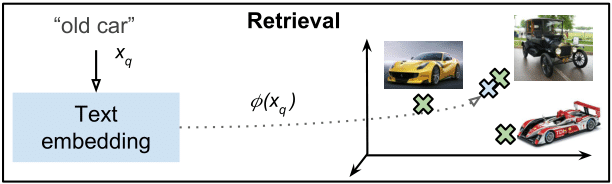
As the regression CNN has learnt to map images to the Word2Vec space, we can do the same nearest words experiment we did with text but with images. That is, retrieving the images that people associate with the word “Barcelona” and the word “ “:
Generic
Barcelona:




Gaudi:




Food
Breakfast: What people have for breakfast in Barcelona? What kind of breakfast people post on Instagram in Barcelona?




Dinner: It’s clear that mostly tourist post with this word, and that they always have seafood paella.




Healthy: What kind of food people think is healthy in Barcelona?




Healthy + Restaurant: If you have been in Barcelona, you might recognice some places




Beer:




Differences between languages
Catalonia (en):




Cataluña (es):




Catalunya (ca):




Neighbourhoods:
Poblenou: Lots of flats being promoted now there




Poblesec: A trendy place to have tapas these days




Rambla: Touristic Mercat Boqueria




Gracia: It seems people post a lot of street art photos associated to Gracia




TSNE plots
Inspired by Kaparthy who uses t-SNE to visualize CNN layer features, we use t-SNE to visualize the learnt joint visual and textual embedding. t-SNE is a non-linear dimensionality reduction method, which we use on our 400 dimensional embeddings to produce 2 dimensional embeddings. For each one of the given 400 dimensional visual or textual embeddings, t-SNE computes a 2 dimensional embedding arranging elements that have a similar representation nearby, providing a way to visualize the learnt joint image-text space.
This representation lets us create a 2-Dimensional image where we can appreciate clusters of the images that have been mapped near in the joint space. In practice, images appearing nearer are images that people post with similar words in Instagram. We show images of different dimensions that show different semantic granularity. See the full size images to appreciate the results.



{kind=link}
{kind=link}
{kind=link}
Off topic: This Hover Zoom Chrome addon shows full size images when hovering on them and it’s pretty usefull.
Conclusion
Social Media data can be used to learn joint image-text embeddings from scratch, and those embeddings can be used to do analysis with high social or commercial value. Notice that this kind of experiments could be applied to any other concept instead of Barcelona, if sufficient data can be collected.