Learning to Learn from Web Data
This work was presented in ECCV 2018 MULA Workshop as “Learning to Learn from Web Data through Deep Semantic Embeddings” [PDF]. Refer to the paper to access the full and formal article. Here I explain informally and briefly the experiments conducted and the conclusions obtained.
The article consists on a performance comparison of different text embeddings (Word2Vec, GloVe, Doc2Vec, FasText and LDA) on an image by text retrieval task. To do a fair comparison, a multimodal retrieval pipeline where the text embedding is an independent block, is proposed. The different text embeddings can be adequate to different data or tasks. I focus on researching which ones work better when learning from Web and Social Media data, which consists on images associated to a short text, which can be a sentence or a group of tags. The work also proves that training with noisy and free Social Media data we can achieve state of the art performances in the image by text retrieval task.
Why are you doing this performance comparison?
At the beginning of my PhD I started playing with Social Media data to find what useful things we could learn from it. The first post of this blog Using Instagram data to learn a city classifier is my first published experiment. Then, following the work of my supervisor Lluis Gomez Deep-embeddings of images into text topic spaces (CVPR 2017) I started playing with the text associated to images. Using a similar pipeline as him, and proved that Instagram data was useful to learn an image retrieval system. As I’m doing an industrial PhD and I like applied research, I tried to apply that pipeline to specific problems, such as inferring ingredients from food images. All those works use LDA topic modeling to encode text, and I wondered if that one was the best text embedding to learn from Web and Social Media data. I searched for performance comparisons and I couldn’t found one. So I decided to do it.
The data
I used two training datasets:
-
WebVision: A dataset from the CVPR WebVision challenge (1.0 version), composed of images collected from Flickr and Google images querying with the Imagenet class names. So basically is a noisy version of the ImageNet dataset with 2.4 million images. The text associated to the images included is the image description, the page name and the flickr hashtags.
-
InstaCities1M: A datasets I collected which is presented in this blog post. It is formed by Instagram images associated with one of the 10 most populated English speaking cities. It contains a total of 1M images.
Those datasets where divided in a training set, a validation set and a test (or retrieval) set.
As an only test dataset and to compare my results with other methods, I also used:
- MIRFlickr: It contains 25K images collected from Flickr annotated using 24 predefined concepts.
The pipeline
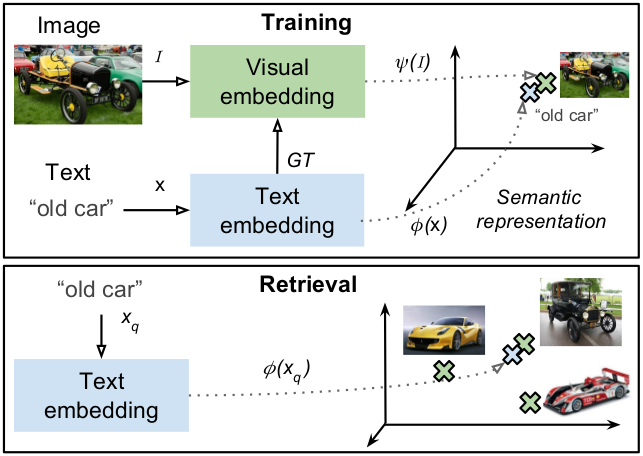
Training:
- We train a text embedding method using all the text in the dataset.
- We compute text embeddings of the training images captions.
- We train a CNN to regress images captions embeddings.
→ With the trained CNN, we compute the embeddings of all the images in the test set.
Testing:
- Compute the embedding of the querying text.
- Compare the query vector with the images embeddings of the test set.
- Retrieve the closest images.
Text Embeddings
- LDA: Latent Dirichlet Allocation learns latent topics from a collection of text documents and maps words to a vector of probabilities of those topics. It can describe a document by assigning topic distributions to them, which in turn have word distributions assigned.
- Word2Vec: Learns relationships between words automatically using a feed-forward neural network. It builds distributed semantic representations of words using the context of them considering both words before and after the target word.
- Doc2Vec. Is an extension of Word2Vec to documents.
- GloVe: It is a count-based model. It learns the word vectors by essentially doing dimensionality reduction on the co-occurrence counts matrix.
- FastText: While Word2Vec and GloVe treat each word in a corpus like an atomic entity, FastText treats each word as composed of character ngrams. So the vector of a word is made of the sum of this character ngrams. This is specially useful for morphologically rich languages. This way, it achieves generating better word embedding for rare words and embeddings for out of vocabulary words.
The Gensim implementation of all the text embeddings was used. For GloVe, the python implementation by Maciej Kula was used.
While LDA and Doc2Vec can generate embeddings for documents, Word2Vec, GloVe and FastText only generate word embeddings. To get documents embeddings from these methods, we consider two standard strategies: First, computing the document embedding as the mean embedding of its words. Second, computing a tf-idf weighted mean of the words in the document.
Visual Embedding
A CNN is trained to regress text embeddings from the correlated images minimizing a sigmoid cross-entropy loss. This loss is used to minimize distances between the text and image embeddings. The GoogleNet architecture is used, customizing the last layer to regress a vector of the same dimensionality as the text embedding. We train with a Stochastic Gradient Descent optimizer with a learning rate of 0.001, multiplied by 0.1 every 100,000 iterations, and a momentum of 0.9. The batch size is set to 120 and random cropping and mirroring are used as online data augmentation. With these settings the CNN trainings converge around 300K-500K iterations. We use the Caffe framework and initialize with the ImageNet trained model to make the training faster. Notice that, despite initializing with a model trained with human-annotated data, this does not denote a dependence on annotated data, since the resulting model can generalize to much more concepts than the ImageNet classes. We trained one model from scratch obtaining similar results, although more training iterations were needed.
The CNN training strategy is the same as explained in this former blogpost.
All the code use in this project is available here.
In later experiments, I have found out that using a contrastive loss (using the image, its caption embedding and a negative caption embedding) leads to better results. In a near future, I will publish a post discussing that.
The experiments
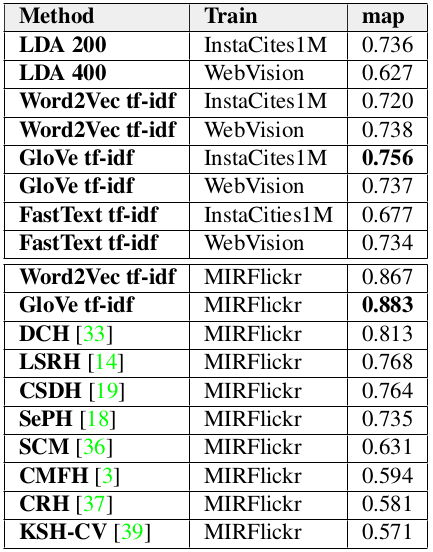
Experiments on WebVision and InstaCities1M datasets
To compare the performance of the different text embeddings in an image retrieval task, we set some queries and inspect visually the top 5 retrieved results for them. They were selected to cover a wide area of semantic concepts that are usually present in Web and Social Media data. Both simple and complex queries are divided in four different categories: Urban, weather, food and people. The simple queries are: Car, skyline, bike; sunrise, snow, rain; icecream, cake, pizza; woman, man, kid. The complex queries are: Yellow + car, skyline + night, bike + park; sunrise + beach; snow + ski; rain + umbrella; ice-cream + beach, chocolate + cake; pizza + wine; woman + bag, man + boat, kid + dog. For complex queries, only images containing both querying concepts are considered correct. Results on transfer learning (ex. training on InstaCities1M and testing on WebVision) are also given.
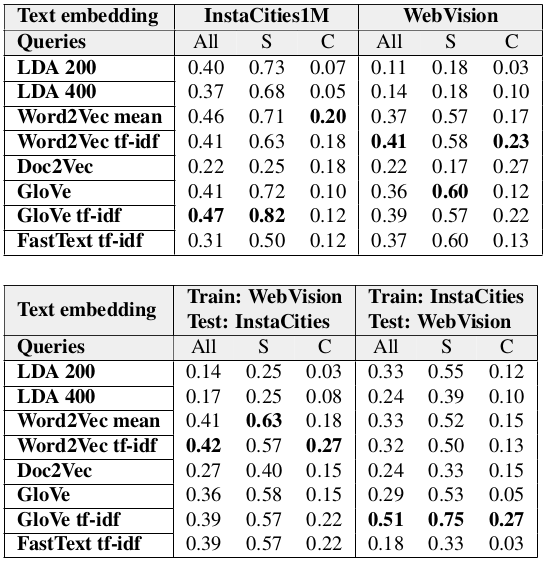
Experiments to compare performance with other methods on MIRFlickr
The MIRFlickr dataset is used to compare our results with other image retrival by text methods. Results show that our method is superior when training with MIRFlickr data, and achieves competitive performance when trained with WebVision or InstaCities1M.
Qualitative results
Following, we show some image retrieval qualitative results. Those have been obtained using the Word2Vec trained model.






Extra qualitative results:




Error analysis
-
Visual features confusion. Errors due to the confusion between visually similar objects. For instance retrieving images of a quiche when querying “pizza”. Those errors could be avoided using more data and a higher dimensional representations, since the problem is the lack of training data to learn visual features that generalize to unseen samples.
-
Errors from the dataset statistics. An important source of errors is due to dataset statistics. As an example, the WebVision dataset contains a class which is “snow leopard” and it has many images of that concept. The word “snow” appears frequently in the images correlated descriptions, so the net learns to embed together the word “snow” and the visual features of a “snow leopard”. There are many more images of “snow leopard” than of “snow”, therefore, when we query “snow” we get snow leopard images. shows this error and how we can use complex multimodal queries to bias the results.
-
Words with different meanings or uses. Words with different meanings or words that people use in different scenarios introduce unexpected behaviors. For instance when we query ”woman + bag” in the InstaCities1M dataset we usually retrieve images of pink bags. The reason is that people tend to write ”woman” in an image caption when pink stuff appears. Those are considered errors in our evaluation, but inferring which images people relate with certain words in Social Media can be a very interesting research.
TSNE plots
Inspired by Kaparthy who uses t-SNE to visualize CNN layer features, we use t-SNE to visualize the learnt joint visual and textual embedding. t-SNE is a non-linear dimensionality reduction method, which we use on our 400 dimensional embeddings to produce 2 dimensional embeddings. For each one of the given 400 dimensional visual or textual embeddings, t-SNE computes a 2 dimensional embedding arranging elements that have a similar representation nearby, providing a way to visualize the learnt joint image-text space.
This representation lets us create a 2-Dimensional image where we can appreciate clusters of the images that have been mapped near in the joint space. We show images of different dimensions that show different semantic granularity. See the full size images to appreciate the results.




Download t-SNE from InstaCities1M 2k, 4k
{kind=link}
{kind=link}
Download t-SNE from WebVision 2k, 4k
{kind=link}
{kind=link}
Off topic: This Hover Zoom Chrome addon shows full size images when hovering on them and it’s pretty usefull.
Conclusions
This work proves that Web and Social media data can be used to train in a self-supervised way the proposed image retrieval by text pipeline achieving competitive performance over supervised methods. The comparative between text embeddings shows that GloVe and Word2Vec methods are superior when learning from Web and Social Media data.