Using Instagram Data to Learn a City Classifier
Why is this an interesting experiment?
One of the bottlenecks of machine learning is the availability of annotated data. Deep learning techniques are data hungry and, despite the existence of huge annotated datasets as Imagenet and tools for human annotation as Amazon Mechanical Turk, the lack of data limits the application of deep learning in specific areas. A common strategy to overcome that problem is to first train models in general datasets as Imagenet and then fine-tune them to other areas using smaller datasets. But still we depend on the existence of annotated data to train our models. An alternative for that is learning from free existing non-human annotated data. Web and social media offer tons of images accompanied with other information, as the image title, description or date. This data is noisy and unstructured but it’s free and nearly unlimited. I’ve been working in algorithms that can learn from this noisy and unstructured data.
Dataset creation
I’ve have created a huge dataset of social media images with associated text, InstaCities1M. It’s formed by Instagram images associated associated with one of the 10 most populated English speaking cities all over the world. It has 100K images for each city, which makes a total of 1M images. The interest of this dataset is: First that is formed by recent social media data. The text associated with the images is the description and the hashtags written by the photo up-loaders. So it’s the kind of free available data that would be very interesting to be able to learn from. Second, each image is associated to one city, so we can use this weakly labeled image classes to evaluate our experiments.
Cities used: London, New York, Sydney, Los Angeles, Chicago, Melbourne, Miami, Toronto, Singapore and San Francisco.
To download the images from Instagram I used InstaLooter, a simple python script that parses the Instagram web without the need API access (The instagram API is only available for approved apps). You can download images quite fast for that, depending on what do you search. I simply did queries with the city names, and I got the 1M images after 2 weeks and some problems.
The code I used to download images from Instagram is available here.
That’s social media data, so it’s very noisy. Instagram does the search by the text associated to the image, and not all images that have the word “london” in the description are from london. Overmore, from the images that were taken in London, only some of them will be representative of the city. We cannot infer that a photo of a dog taken in London inside a house is Londoner (or maybe we can if that’s a typical british race or furniture). ¿What would happen if we used images taken in London GPS coordinates instead of accompanied with the word London? Ok all images would be from London but a lot less representative.
Also, there are some bots and image repetitions (Don’t try this experiment with twitter, bots will ruin them). I did some checks using image size and weight and I found that 98.3% of the images were unique. I removed the repeated ones.
Training
I trained an AlexNet using Caffe for classifying the images between the 10 cities. I first resized the dataset to 300x300 for efficiency purposes (It might be better to resize it keeping the images aspect ratio, but here I didn’t). I applied online data augmentation: 224x224 random crops and mirroring with 50% probability. I initialized from the Imagenet trained model and fine-tuned only the last 3 convolutional layers and the fully connected layers (other layers are frozen). I used a learning rate of 0.001.
I got a classification accuracy of 30%. That might be not so far from human accuracy, since most of the images are not representative of the city. We can observe that some overfitting starts to appear. So applying a more aggressive data augmentation could improve the performance.
The code for the CNN training in PyCaffe is available here.
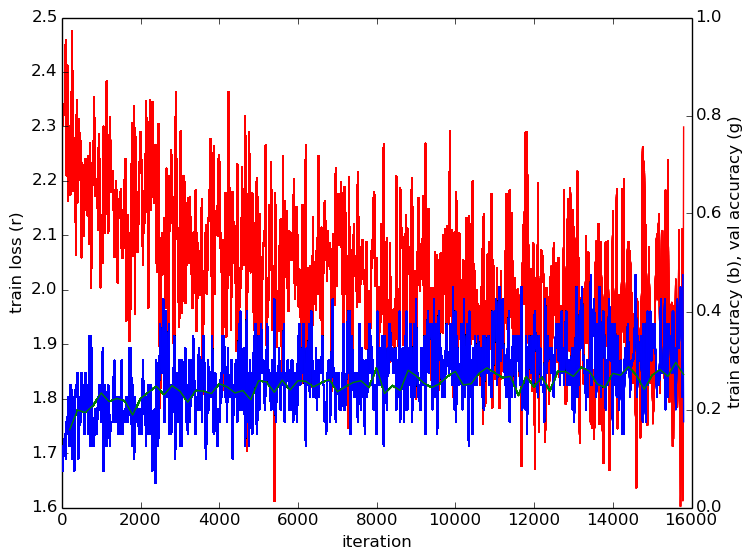
The numbers
Accuracy: 26.3%
Accuracy per class:
london = 0.296673455533
newyork = 0.212831585441
sydney = 0.243430152144
losangeles = 0.182625237793
chicago = 0.214053350683
melbourne = 0.235893949694
miami = 0.332631578947
toronto = 0.213836477987
singapore = 0.415828303152
sanfrancisco = 0.291230366492
What can the net identify?
The net has learned to identify some interesting patterns beyond cities touristic stuff. It learned cities typical architecture, food or characters. If we train a net with social media images associated to one concept, the net will learn to identify the kind of images that people associate to that concept instead of learning how that concept looks like. That can lead to very interesting applications.
London TP









New York TP



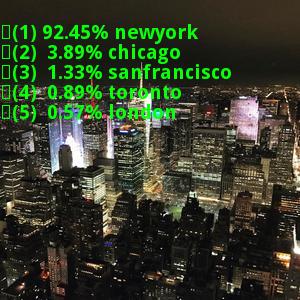





A sample of New York misclassified images:



That was a toy experiment I did while creating the InstaCities1M dataset, which I’m using in more complex stuff that I will publish soon.
By the way, did not seem weird to you AlexNet being overfitted with a 1M dataset? These experiment has been done with a 20% subset of InstaCities1M, so 200K images. That was because I did it while I was still building the dataset. Would it overfit with the 1M dataset?