Location Sensitive Image Retrieval and Tagging
This work has been published in ECCV 2020. Refer to the paper to access the full and formal article. Here I explain informally and briefly the experiments conducted and the conclusions obtained.
The code used in this work is available here. The ECCV reviews and rebuttal of this paper are available here.
In this work we train a neural network to score triplets of image, hashtag and geolocation by plausibility, and exploit that model to retrieve images related to a given hashtag and near to a given location, and to tag images exploiting both their visual information and their geolocation.
We train on a large scale dataset of Web (Flickr) images with associated tags and geolocations: YFCC100M. We find that, to train the model for the retrieval task, it is a must to balance the query hashtag and location influence in the ranking, and we design a technique to do that. We demonstrate that the retrieval model can be trained to retrieve images related to a query hashtag and near to a query location at different location granularities, and that the tagging model exploits location to outperform location agnostic tagging models.

We follow this steps:
-
Learn images and tags representations exploiting the image-tags associations.
-
Train LocSens, a model that ranks triplets of images, tags and locations by plausibility, exploiting the representations learnt in step 1.
-
Location sensitive image retrieval: LocSens can rank images given a tag+location query.
-
Location sensitive image tagging: LocSens can rank tags given an image+location query.
If you prefer video format, here is the video I made to present the article in (online) ECCV 2020
Data
In this work we use the YFCC100M dataset, which contains 100 Million images with associated tags and geolocations (latitude and longitude), and other metadata we don’t use in this work. We filter out the images without geolocation, images without tags, etc., and end up with 25 million images. We create a large hashtag vocabulary consisting on the most frequent 100k tags. For more details about the vocabulary creation, the splits used and the data preprocessing, read the paper. In the LocSens GitHub there are also the original splits and vocabulary. We will input the geolocation to our model as raw latitude and longitude, but normalized to range between [0-1]. Note that 0 and 1 latitude fall on the poles while 0 and 1 represent the same longitude because of its circular nature and falls on the Pacific. So, despite other location encodings could be considered, this straightforward normalization seems to be, by chance, adequate.
Learning with Hashtag Supervision
The first step of this work is to learn image (and tags) representations (in a location agnostic setup). This representations will be after input to LocSens, which will be trained with pre-computed visual and tags representations. We have 25M images with an average of 4.25 hashtags. The tags are noisy and highly unbalanced. We benchmark different training strategies to learn images and tags representations, in what we call a learning with hashtag supervision task. Here I briefly mention the setups tried and the results, but I strongly recommend you to read the paper if you are interested in this comparison.
-
MCC. We setup the problem as a Multi-Class Classification problem. At each iteration one of the images tags is selected as positive, and a CNN is trained with a Softmax activation with that positive tag and a Cross-Entropy Loss. Before the classification layer, we add a 300-dimensional layer, which allows us to learn both images and tags embeddings. Learn more about MCC in my former blogpost.
-
MLC. We setup the problem as a Multi-Label Classification, by splitting it on 100K independent binary classification problems with Sigmoid activations and a Cross-Entropy Loss. Learn more about MLC in my former blogpost.
-
HER. We compute the GloVe representations of each one of the image hashtags, sum them and train a CNN to regress the sum of those representation. This setup is similar to the one used explained in this blogpost, but using a cosine embedding loss.
The following table shows the results of this three setups on image retrieval an image tagging. The MLC training was very unstable due to class imbalance. We tried different techniques to balance the classes, but couldn’t achieve consistent results. MCC classification outperforms the other methods by a big margin in both tasks, despite it is counter intuitive, because it is setting a naturally multi-label task (multiple positive hashtags per image) as a multi-class task (a single positive class per image.) Please read the paper for more details of this training, evaluation details and results analysis.


LocSens
The proposed LocSens model has as inputs an image+tag+location triplet. LocSens mapps the pre-computed image representations, tags representations, and location to 300-dimensional representations, L2 normalizes them and concatenates them. Then it jointly processes the multimodal representations with a set of fully connected layers until it computes a score for the triplet. We tried different techniques to merge the visual, tag and location information, but the only one that resulted in a correct optimization of the model was mapping the three modalities to the same dimensionality and normalizing them before the concatenation. Concatenating the location on a lower dimensionality caused the model to ignore it, and different attention and weight initialization techniques were tried to avoid so without success. The next figure shows the architecture of LocSens.
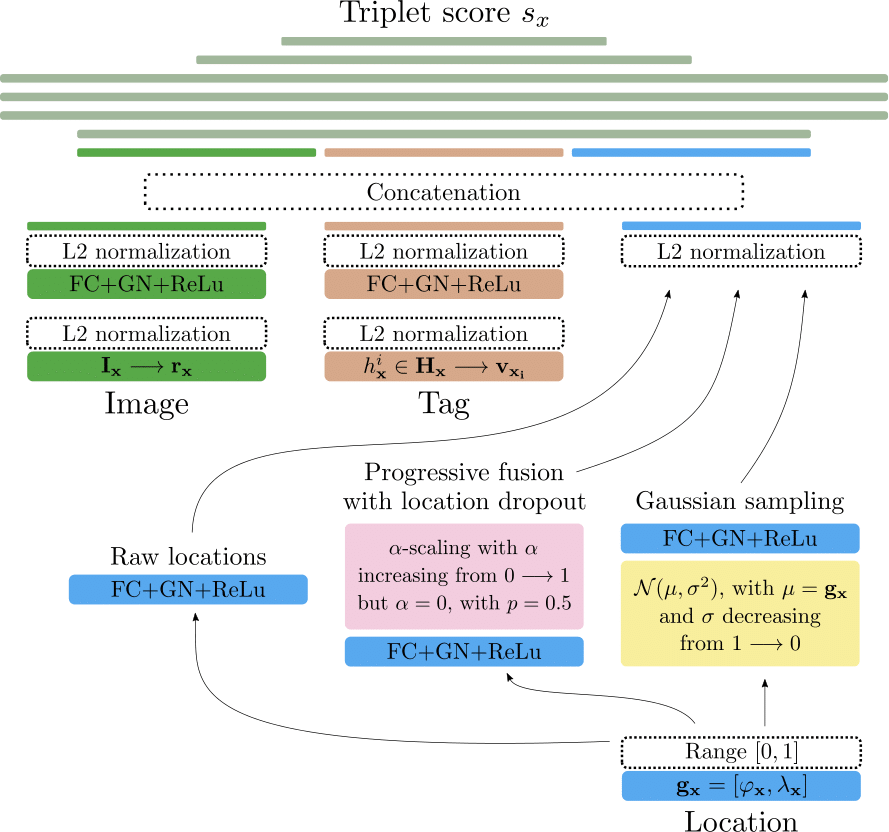
LocSens is trained with a Ranking Loss in a siamese-like setup to rank positive triplets higher than negative triplets. If you want to learn more about ranking losses and metric learning, I recommend you reading this blogpost. We found that the optimal strategy to train LocSens was different for tagging and retrieval, so next we explain both strategies separately:
LocSens Training for Tagging
To create a negative triplet, we randomly replace the image or the tag of the positive triplet. The image is replaced by a random one not associated with the tag, and the tag by a random one not associated with the image. We use 6 negative triplets per positive triplet averaging the loss over them and a batch size of 1024.
LocSens Training for Retrieval
We found that the performance in image retrieval is significantly better when all negative triplets are created replacing the image. This is because the frequency of tags is preserved in both the positive and negative triplets, while in the tagging configuration less common tags are more frequently seen in negative triplets.
Balancing Location Influence on Ranking
We found that in image retrieval LocSens was retrieving images that were always near to the query location, but not strongly related with the query tag. In other words: The location influence in the ranking was very high. To solve that, we designed two strategies to balance the location and tag influence in the training:
-
Progressive Fusion with Location Dropout. We first train LocSens but silencing the location modality hence forcing it to learn to discriminate triplets without using location information. Once the training has converged we start introducing locations progressively. In order to force the model to sustain the capability to discriminate between triplets without using location information we permanently zero the location representations with a 0.5 probability. We call this location dropout.
-
Location Sampling. We propose to progressively present locations from rough precision to more accurate values while training advances.
For each triplet, we randomly sample the training location coordinates at each iteration from a 2D normal distribution with mean at the image real coordinates and with standard deviation decreasing progressively during the training.
LocSens Image Retrieval
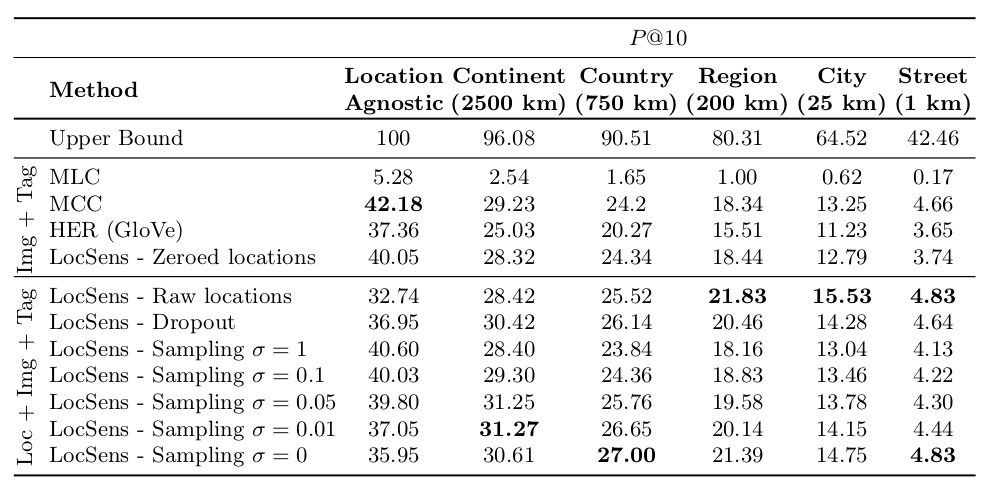
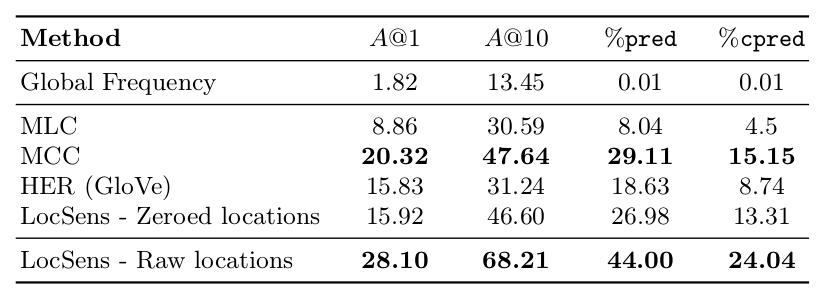
We design a location sensitive image retrieval evaluation where both the relations of the retrieved images with the query tag and the query location is evaluated. We consider a retrieved image correct if it contains the query hashtag in its groundtruth and if its geolocated near to the query location (the distance is smaller than a threshold). We evaluate using different distance thresholds, which we call location granularities. The following table shows the results of the location agnostic models and LocSens with the different location balancing techniques.
The following figure shows similar information as the table, but it allows us to easily understand how the the location sampling technique balances the location infuence in the ranking.
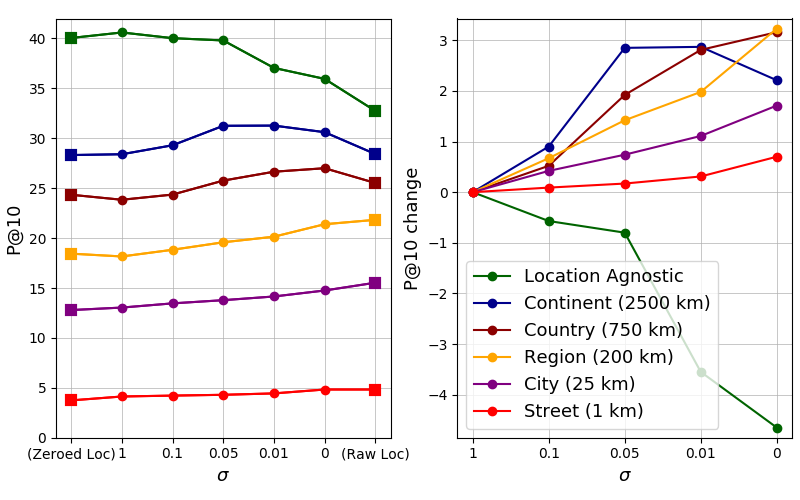
The results show how the LocSens - Raw Location model, which has as input the original locations during the whole training, is the one performing best at fine granularities (street level, city level and region level). However, its performance is significantly worse in location agnostic retrieval and coarse granularities (continent, country). That is because the location has a big influence in the ranking, and the model is retrieving images that are often near to the query location, but with a weaker relation with the query hashtag. The proposed techniques to balance the location influence on the ranking, allow a better compromise between retrieving images related to the query tag and near to the given location. The LocSens - Location Sampling technique allows moreover training a model sensible to the different location granularities. Please read the paper for a more detailed explanation and analysis of the results and the location balancing techniques.
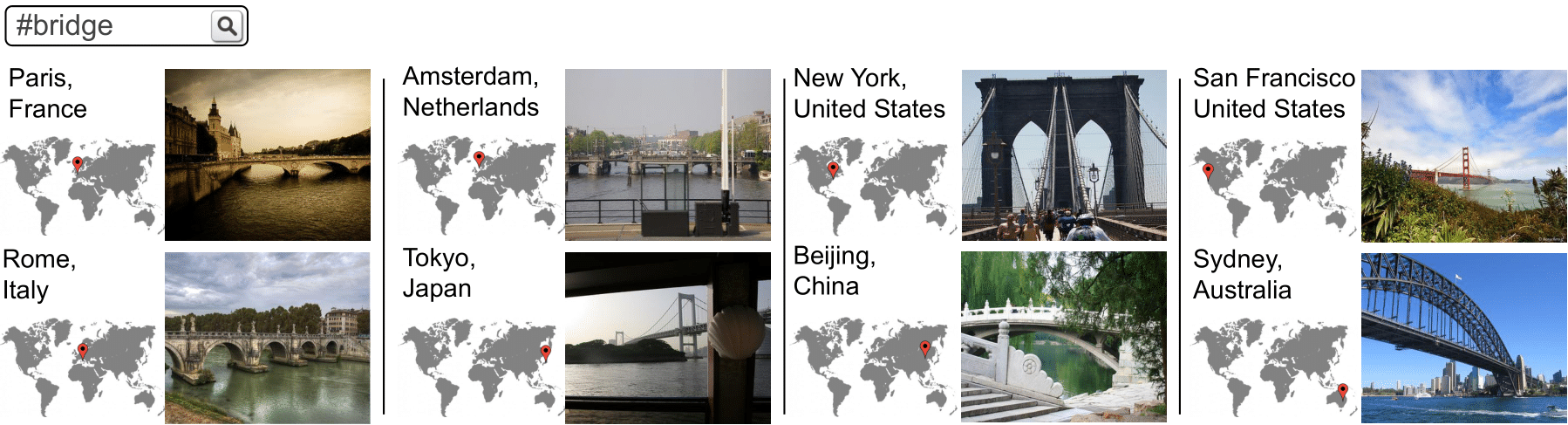
The next figure shows qualitative retrieval results of several hashtags at different locations. It demonstrates that the model successfully fuses textual and location information to retrieve images related to the joint interpretation of the two query modalities, being able to retrieve images related to the same concept across a wide range of locations with different geographical distances between them. LocSens goes beyond retrieving the most common images from each geographical location, as it is demonstrated by the winter results in Berlin or the car results in Paris.

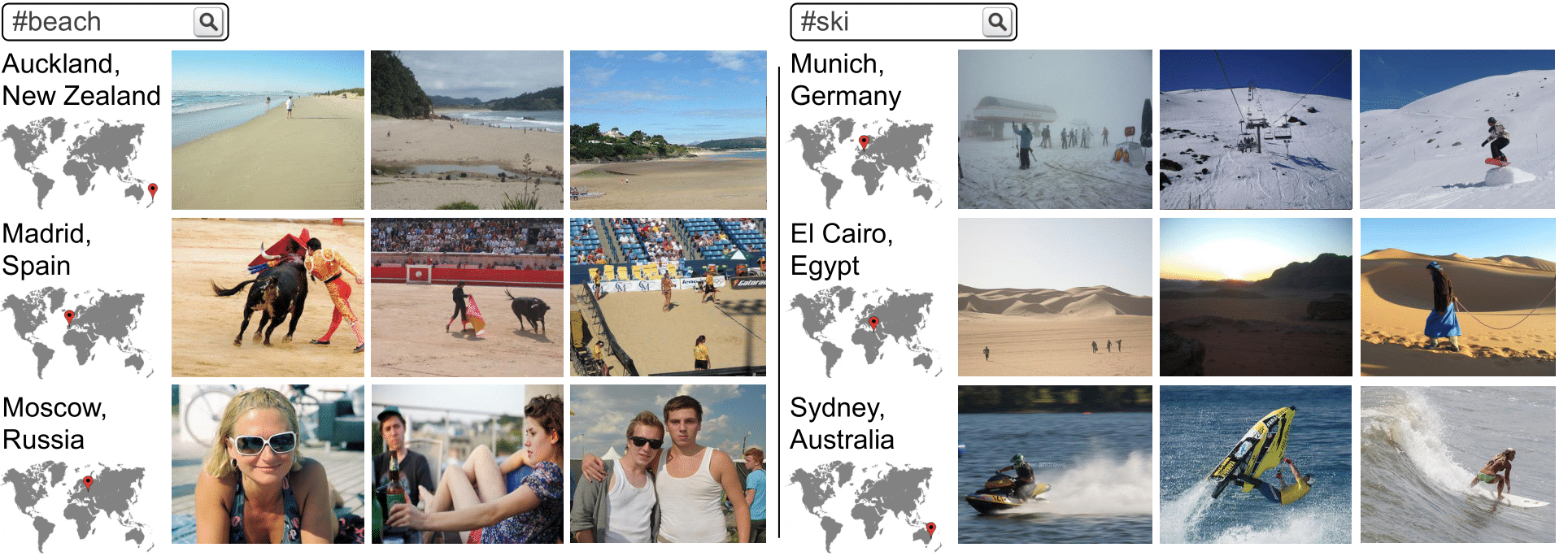
The next figure shows results for hashtag queries in different locations where some queries are incompatible because the hashtag refers to a concept which does not occur in the given location. When querying with the beach hashtag in a coastal location such as Auckland, LocSens retrieves images of close-by beaches. But when we query for beach images from Madrid, which is far away from the coast, we get bullfighting and beach volley images, because the sand of both arenas makes them visually similar to beach images. If we try to retrieve beach images near Moscow, we get scenes of people sunbathing. Similarly, if we query for ski images in El Cairo and Sydney, we get images of the desert and water sports respectively, which have visual similarities with ski images.
LocSens Image Tagging
The evaluation of image tagging is more simple and standard: LocSens has as inputs visual and location information but the objective is the standard one in an image tagging task, which is predicting the groundtruth hashtags. The objective of this evaluation is to prove that LocSens successfully exploits location information to outperform location agnostic image tagging models. The following table shows image tagging results of the location agnostic models and LocSens.
Please refer to the paper for a detailed analysis of this tagging results. In the supplementary material we provide a more extensive and interesting analysis on how LocSens exploits the location information to improve image tagging.
The next figure shows a comparison of the tagging results of MCC and LocSens, that demonstrate how the later successfully processes jointly visual and location information to assign tags referring to the concurrence of both data modalities. As seen in the first example, besides assigning tags directly related to the given location (london) and discarding tags related to locations far from the given one (newyork), LocSens predicts tags that need the joint interpretation of visual and location information (thames).

The next figure shows LocSens tagging results on images with different faked locations, and demonstrates that LocSens jointly interprets the image and the location to assign better contextualized tags, such as caribbean if a sailing image is from Cuba, and lake if it is from Toronto. In the example of an image of a road, it predicts as one of the most probable tags carretera (which means road in spanish) if the image is from Costa Rica, while it predicts hills, Cumbria and Scotland if the image is from Edinburgh, referring to the geography and the regions names around. If the image is from Chicago, it predicts interstate, since the road in it may be from the United States interstate highway system.

Future Work
-
Learning with tags supervision. Our research on learning image representations with hashtags supervision concludes that a Multi-Class setup with Softmax activations and a Cross-Entropy loss outperforms the other baselines by a big margin. A research line to uncover the reason for this superior performance and to find under which conditions this method outperforms other standard learning setups, such as using a Multi-Label setup with Sigmoid activations, would be very interesting for the community.
-
More efficient architectures. The current efficiency of the method is a drawback, since for instance to find the top tags for an image and location query, we have to compute the score of the query with all the hashtags in the vocabulary. An interesting research line is to find architectures for the same task that are more efficient than LocSens. As an example, we have been researching on tagging models that learn a joint embedding space for hashtags and image+location pairs, which at inference time only need to compute a distance between an image+location query embedding and pre-computed tags embeddings, being much more efficient. The drawback of such architectures is, however, that the same model cannot be used for tagging and retrieval as LocSens can: A retrieval model with this architecture would have to learn a joint embedding space for hashtags+location pairs and images.
-
Information modalities balance. In the paper we propose a location sampling strategy useful to balance the location influence in the image ranking. Experimentation on how this technique can be exploited in other multimodal tasks would be an interesting research line.
-
Experimentation under more controlled scenarios. In this work we have focused on learning from large scale Social Media data. Further experimentation under more controlled scenarios where the location information is meaningful in all cases is another interesting research setup to evaluate the same tasks of location sensitive image retrieval and tagging.
Read the ECCV2020 paper for more details about this work.