Learning from #Barcelona what Locals and Tourists post about its Neighbourhoods
This work was presented in ECCV 2018 MULA Workshop as “Learning from #Barcelona Instagram data what Locals and Tourists post about its Neighbourhoods” [PDF]. Refer to the paper to access the full and formal article. Here I explain informally and briefly the experiments conducted and the conclusions obtained.
Motivation
I research on designing pipelines that can learn from web data (images with associated text) in a self-supervised way. I wanted to apply this pipeline to a real life problem to test how it works beyond scientific datasets and to show its potential applications. That’s way I collected a dataset of Instagram images associated with Barcelona, InstaBarcelona. In the post What do people think about Barcelona? I explain how I trained an image by text retrieval system with this data, and how it can be used to retrieve which images Instagram users relate with Barcelona and any other text concept. I presented this results at ForumTurisTIC in Barcelona (check this post) and got a big interest from the tourism industry.
Barcelona has a big problem with tourism. It receives around 10 million tourists every year. That causes conflicts between tourists and the tourism industry and other local organizations, conflicts that are highly concentrated on certain neighborhoods with requested tourist attractions. In this work we learn what locals and tourist highlight about every neighbourhood. The objective is to provide a tool to analyze which neighbourhoods have bigger differences in locals vs tourist activity, which ones concentrate most of the tourism and why. The proposed pipeline can be extended to any other city or subject, if enough Social Media data is available.
InstaBarcelona Dataset
To perform the presented analysis we gathered a dataset of Instagram images related to Barcelona uploaded between September and December of 2017. That means images with a caption where the word ”Barcelona” appears. We collected around 1.3 million images. In order to discard spam and other undesirable images, we performed several dataset cleanings (check details in the paper). To infer the language of the captions Google’s language detection API was used. The resulting dataset, contains 597,766 image-captions pairs. From those pairs 331,037 are English publications, 171,825 Spanish publications and 94,311 Catalan publications.

Proposed pipeline
- We split the data depending on whether it contains captions in a local language,Spanish and Catalan, or English, which we consider to be locals vs tourists publications.
- We count the mentions of the different districts and neighborhoods and the most used words in each data split. The results confirm that the language-separate treatment can be extrapolated to a locals vs tourists analysis.
- We train a semantic word embedding model, Word2Vec, for each language and show the words that locals and tourists associate with different neighborhood names
- Using the semantic word embeddings as a supervisory signal, we train a CNN thanlearns relations between images and neighborhoods.
- Using the trained models in a retrieval approach with unseen data we show, for each language, the most related images to different neighborhoods. Results show interesting differences between the visual elements that locals and tourists associate to each neighborhood.
Textual Analysis
Counting Districts and Neighbourhoods Mentions
We count the number of mentions per district and neighbourhoods respect to the total number of mentions per each language split. Results show which neighbourhoods concentrate most mentions in each language, which is a good indication of which ones concentrate more tourism.
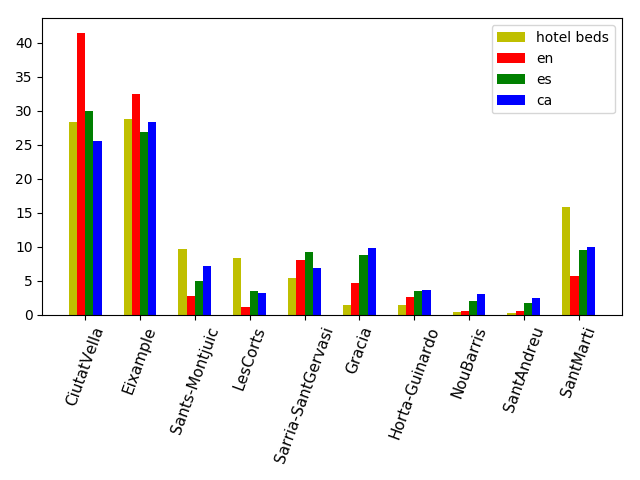
The above figure shows how Ciutat Vella and Eixample are the most mentioned districts in the three languages. This makes sense since those districts concentrate the most representative and touristic Barcelona attractions, and people tend to post more on Instagram when they are traveling and to use the word Barcelona when they are uploading a Barcelona representative image. The % of images that this most touristic districts concentrate is much bigger for English than for local languages, especially for Ciutat Vella, Barcelona’s old town, the most touristic district.
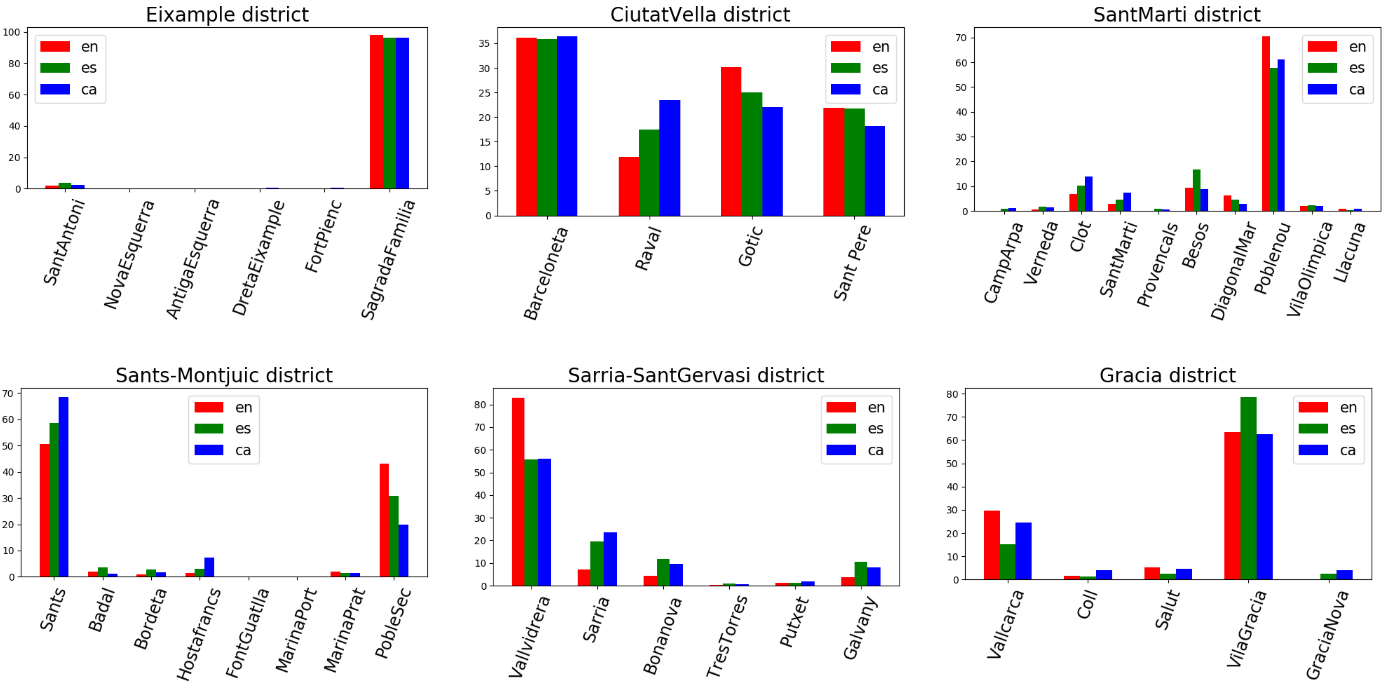
The Ciutat Vella plot shows that all its neighborhoods are highly popular among all tourists and locals, being La Barceloneta, its beach area, the most mentioned one in all languages. La Barceloneta is a former fisher neighborhood which receives now a lot of tourism attention. El Gotic, Barcelona’s old town, concentrates a markedly higher % of publications in English than in other languages, and is in fact the neighborhood most affected by tourism in Barcelona. Sant Pere, commonly known as El Born, is also mentioned by tourists and locals in a similar %. El Raval neighborhood is a very multi-cultural area, which has traditionally been considered dangerous due to drug presence and delinquency. However, its geographical situation close to Barcelona’s old town has transformed it lately into a more touristic area. The plot shows that El Raval is still an area more popular among locals.
The Sant Martı́ district plot, shows that El Poblenou is the most popular neighbourhood in it, specially among english speakers. El Poblenou is a former industrial neighbourhood which lately is getting popular due to the 22@ plan, which aims to concentrate in that area technological firms headquarters and design studies. Due to its modernization and geographical situation in the seaside, El Poblenou is in danger to become a neighborhood with overcrowded tourism, as well as happened with La Barceloneta. This analysis strengthens that hypothesis, showing that El Poblenou and Diagonal Mar are the only neighborhoods among Sant Martı́ where the English % of posts is superior to the ones of local languages.
Word2Vec
Word2Vec learns vector representations from non annotated text, where words having similar semantics have similar representations. We train a different model for each one of the analyzed languages: English, Spanish and Catalan. The objective is to learn the different contexts where the authors use words depending on their language.
Words associated to districts (and to other terms) in each language
Closest words of the English trained Word2Vec are shown in red, of the Spanish onein green, and of the Catalan one in blue.


Tourist publications mentioning El Born relate this district to Barcelona’s old town, while locals publications mention its promenade, its market or its culture center (CCM). When mentioning El Raval, tourists publications mention its museums and other nearby districts. On the contrary, locals publications talk about its cultural activity, its promenade or its drug presence problem.
When mentioning Food English speakers write along Spanish most characteristic dishes, while locals write about more daily meals. When mentioning Neighborhood, tourists talk about its restaurants or appearance, while locals talk more about its people.
Visual Analysis
An image worths a thousand words. Word2Vec allows us to find the words that authors relate neighborhoods when using different languages That is possible because Word2Vec learns word embeddings to a vectorial space where semantic similar words (words appearing in similar contexts), are mapped nearby. Img2NeighCtx (Image to Neighborhood Context) is a Convolutional Neural Network that, learning from images and associated captions, allows us to find the images that authors relate to the different neighborhoods when using different languages.
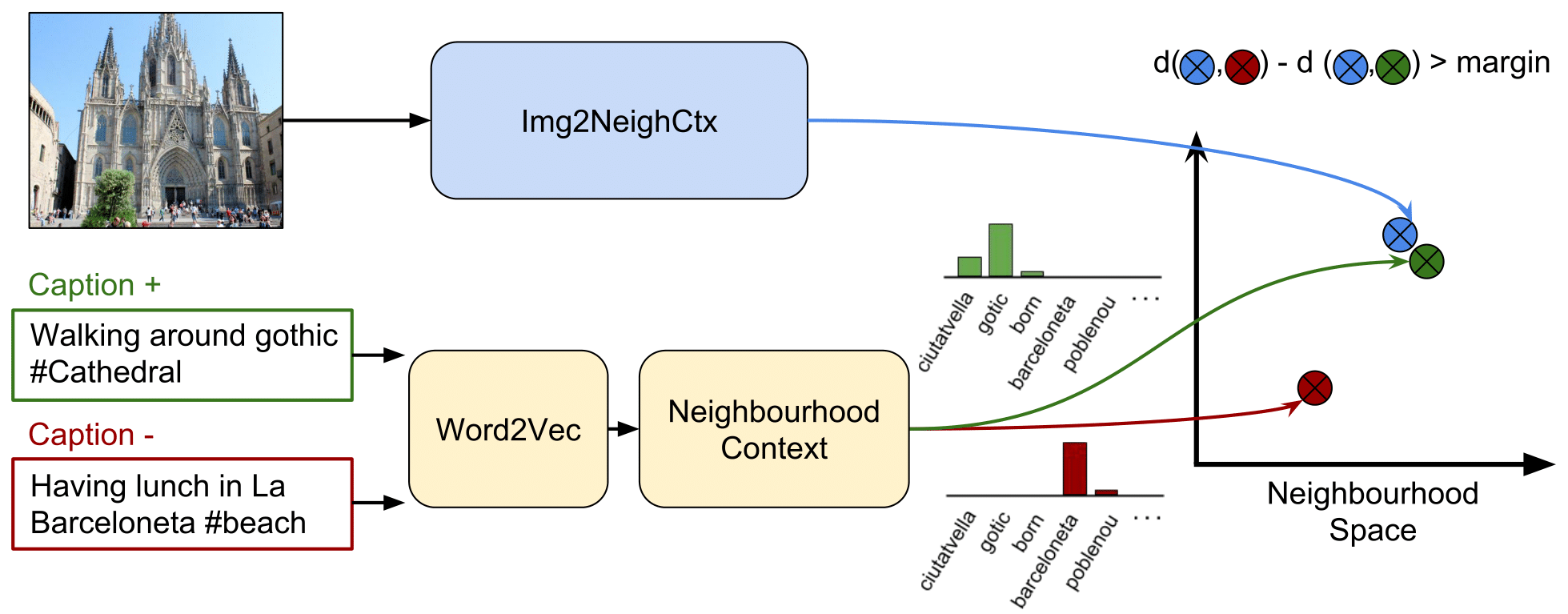
Img2NeighCtx is a GoogleNet based CNN that learns to infer Neighbourhood Similarities from images. The last classification layer is replaced by a fully connected layer with 82 outputs, which is the dimensionality of the Neighborhood Space, and uses a ranking loss to learn to embed images with similar captions Neighborhood Contexts nearby. Read the paper for more details!
Images associated to districts
Once Img2NeighCtx has been trained to embed images in the Neighborhood Space, it can be used in a straightforward manner in an image by neighbourhood retrieval task. The CNN has learned from the images and the associated captions to extract visual features useful to relate images to the different neighborhoods. Using as a query a neighborhood represented as a one hot vector in the Neighborhood Space, we can infer the kind of images that Instagram users writing in English, Spanish or Catalan relate to that neighborhood.

When talking about El Born (Sant Pere), tourist tend to post photos of bikes, since there are many tourist oriented stores offering bike renting services there, while locals tend to post photos of its bars and streets. When posting about El Poblesec 9, tourist tend to post photos of the food they have in its popularity increasing restaurants, while locals tend to post photos of themselves, its bars or its art galleries. When posting about El Poblenou 9, the kind of images people post using the three languages are similar and related to design and art. This is because El Poblenou neighbourhood has been promoted as a technology and design hub in Barcelona, following the 22@ plan. This plan has attracted many foreign workers to live in the area. Therefore, and in contrast to other neighborhoods, the majority of English publications related to El Poblenou are not from tourists but from people that have settled here, and appear to have the same interests in El Poblenou as the Catalan and Spanish speakers.
Images associated to other concepts
Img2NeighCtx is very useful to retrieve images associated to each neighborhood in each one of the languages. In a similar way we trained Img2NeighCtx to predict Neigh-borhood Contexts from images, we can train a net to directly embed images in the Word2Vec space. (This is the same we did in this former post)

When using the word food, tourist tend to post photos of themselves in front of ”healthy” and well presented dishes or seafood. As a contrast, locals tend to post photos where only the food appears, and it tends to be international and more diverse. For friends tourist tend to post photos of a group of friends in the beach, while locals tend to appear around a table, though they are more diverse. Associated with the word views, tourists post photos of Barcelona’s views taken from popular places (Montjuic and Park Güell). As a contrast, locals photos are more diverse and include photos taken from houses and of other Barcelona areas, such as the port. When using the word market, tourist photos are mainly from Mercat de la Boqueria, an old market in Barcelona’s old town that has turned into a very touristic place. Meanwhile, locals photos are more diverse and include markets where people do their daily shopping. In general, English speakers images are much less variant than local languages speakers images, and more concentrated in popular spots. That proves that the assumption that English speakers images correspond mainly to tourists is true, and also that tourism is strongly concentrated in certain Barcelona areas
Conclusions
Extensive experiments have demonstrated that Instagram data can be used to learn relations between words, images and neighborhoods that allow us to do a per neighborhood analysis of a city. Results have shown that the assumption that English publications represent tourists activity and local languages publications correspond to locals activity is true. Both the textual and the visual analysis have demonstrated to reflect the actual tourists and locals behavior in Barcelona. The retrieval results for both Img2NeighCtx and Img2Word2Vec nets have been obtained in blind and image only test sets, which proves that similar results can be obtained with external images. Moreover, Img2Word2Vec can be used to obtain results for any term in the vocabulary. In this work the InstaBarcelona dataset has been used. However, models can be scaled to larger datasets, since both Word2Vec and CNNs scale well with big data. The experiments can also be extended straightforward to other cities or subjects.
The code used in the project is available here