Learning Image Topics from Instagram to Build an Image Retrieval System
Introduction
In the Using Instagram data to learn a city classifier post we talk about the importance of designing algorithms capable to learn from web and social media data.
Web and social media is an infinite source of images associated with text and other data. We can use that associated data to learn image representations, avoiding the dependence of human annotated data, one of the bottlenecks of machine learning.
There we explain the creation of the InstaCities1M dataset, and we demonstrate how we can learn to classify images between 10 cities using Instagram data.
Here,we go beyond: We learn a semantic meaningful embedding of text and images using Instagram data. That lets us project both text and images to the same space. Taking profit of those projections, we design a retrieval by text system, that probes that we learnt quite fine-grained topics from Instagram weak-labeled data.
Putting images and text in the same space
We want to create a common space for words and images to be able to perform multimodal retrieval. The application will be the retrieval of images by text. The pipeline, explained in detail below, is the following:
Train a LDA to create topics from text. Infer topic distribution of the caption associated to each image. Train a CNN to regress topic probabilities for images. As the image topic distribution groundtruth, we use the topic distribution of the associated caption.
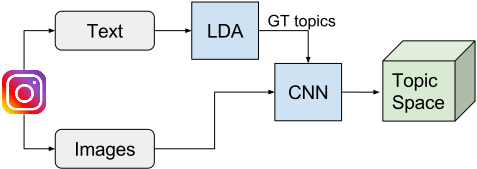
We split the dataset in 800K training, 50K validation and 150K test.
The topic creation: LDA
To create topics from text we use Latent Dirichlet Allocation. LDA is a topic model where, if observations are words collected into documents (word of Instagram image descriptions), it posits that each document is a mixture of a small number of topics. So given all the documents, it creates a given number of topics where every seen word has a weight. Then it can infer a topic distribution for a given word or text (average of text words distribution).
There are several decisions regarding the LDA model training. We have to choose the number of topics, the chunksize (every how many iterations update the model -batch size-) and the passes over the whole corpus. Furthermore we need to define the text preprocessing. Also, usually the less frequent words in the corpus are removed. All that parameters influence the computational requirements to train the LDA, which are quite high when using a large vocabulary or number of documents.
The LDA basically creates topics from the training text taking into account which words appear together in the text pieces. Those topics have a semantic sense. For instance, one topic can gather words about cooking and another one about sports. Then the LDA can infer a topic distribution for any piece of text. That topic distributions codes how a piece of text is related to each one of the topics.
Text preprocessing
1- Replace # with spaces
2- Remove all but letters and numbers
3- Turn all to minus
4- Remove stop english words
5- Stemmer
LDA training parameters
I tried different training parameters and number of topics, but the final choice was:
num_topics = 500
passes = 1 # Passes over the whole corpus
chuncksize = 50000 # Update the model every x documents
repetition_theshold = 150 # Remove words with less than x instances
I used gensim LDA multicore and the training took ~1day in a machine with an Intel(R) Core(TM) i7-5820K CPU @ 3.30GHz with 64GB of RAM and 12 threads. Notice that the RAM usage was high, ~50GB.
The python code for LDA trainning and inferring is available here.
Getting the image GT topic distribution
We will use as image GT topic distribution the topic distribution of the text associated to images. To compute it, we just preprocess the text the same way we did it in the LDA training and infer it using the LDA model.
Training a CNN to regress topic probabilities
We train a regression CNN to infer topic distribution from images. The net has as inputs an image and the topic distribution given by its associated text, which is used as ground truth. The trained net will let us project any image to the topic space.
The CNN used is a GoogleNet and the framework Caffe. We also experimented with CaffeNet, VGG16 (which lead to worse results) and ResNet-50 (which did not learn -it has not been tested extensively in Caffe).
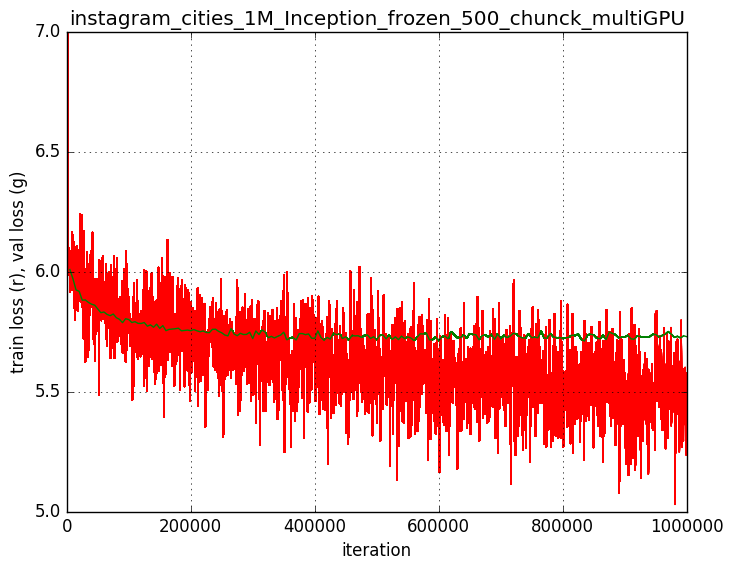
I resized the dataset to 300x300 and did online data augmentation randomly cropping 224x224 image patches and mirroring with probability 50%. I trained using Sigmoid Cross Entropy Loss initializing from the ImageNet trained model.
The GoogleNet have 3 losses at different network layers to help propagate the loss to the first layers. After some experiments I concluded that the training was faster and lead to a better result removing the 2 first losses, so using only the loss in the final fc layer (which of course I re-dimensioned to 500, the number of topics). Overmore I froze the learning rate of all the layers before the loss 2.
To disable the loss 1 and 2 of GoggleNet, you can simple set their weight loss to 0. But it’s advisable to remove the loss layers and also the convolutional and fully connected layers used only by that loss. That way you make the model lighter and you’ll be able to train faster and use a bigger batch size.
I trained it using a cluster with 4 Nvidia GTX 1080 Ti. THe batch size was set to 140 in each GPU, so it makes an effective batch size of 560. The learning rate was set to 0.003.
I have to say that the rule that Facebook stated (If you increase the batch size by k, you can increase the learning rate by k and you’ll get the same performance) was not fulfilled here. I couldn’t increase the learning rate that much. Though, the learning was less noisy using a big batch size.
The PyCaffe code to train the topic regression GoogleNet is available here (Single GPU and multi-GPU).
Results: Retrieval by text
I regressed and saved the topic distributions of the 150K test images. Now I can do text queries, compute its topic distribution using LDA and then retrieve the test images with the most similar regressed topic distribution. I use the dot product as the similarity metric. For queries having more than one word, I compute the mean of the words topic distribution.
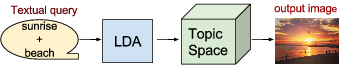
Query by a city name
Despite our setup has nothing to do with cities, we are using a dataset that has each image associated with one city. So we can perform retrieval experiments with the city names and evaluate them analytically. Clearly a net trained for city classification would perform better, but this pipeline (and this results) can be extrapolated to other queries. Metrics used are TOP100 and AP.

Qualitative results
Let’s have a look at the first 3 images retrieved by different concepts, starting with simple queries and ending with complex ones.
“rain”, a simple query. The system in general works well when retrieving single-concept images.



“snow”. Sometimes we get errors in simple queries. We retrieve some squirrels when querying “snow”. Nevertheless they have evolved for years to be able to camuflate there.



“skyline” + “night”. The retrieval works well for some complex queries.



“car” + “yellow”



“sunrise” + “beach”. But most of the times we get images only matching one concept.



“woman” + “bag”. And sometimes we get curious stuff.



Conclusions
The retrieval works well for single-concept queries, though gets confused with some concepts that are visually similar. It also gets confused with concepts that highly related to some social media activity. For instance, the bad results when querying “los angeles” it’s because many baseball images from different places are retrieved. Maybe there was a baseball event in Los Angeles when we compiled the dataset. The same extrange behaviour happens with other concepts.
For two words queries the performance is worse. The system success retrieving images containing two concepts together in those cases where the visual features associated to images are simple (as “yellow + car”) and in those cases where it might have a lot of training data (as “skyline + night”). But it generally fails and retrieve images containing only of the two concepts, which may be more dominant, as happens with “sunrise + beach”.
The multi-modal embedding vs traditional search images engines
In Google, Instagram or Twitter you can search images using text, but the system will only retrieve images from posts that have that text. That has two main drawbacks:
-
Images related to the query word but without the query word in the caption will not be retrieved. Images that are not associated to the word but have a caption that contains the word are retrieved. Ex. image of Paris with the text “From Barcelona to paris” would be retrieved with the query “Barcelona”.
-
The multi-modal embedding system maps the querying text to the same space as the images. So it directly uses image representations in the retrieval, instead of using the text associated to them. In fact, we don’t need text associated to images after the system has been trained.
Beyond object and actions recognition
Usually image retrieval systems are oriented to retrieve images by object presence, combination of objects or objects and their actions. In social media users combine text and images in posts following other rules, which are much more complex. Those rules also vary a lot over time. For instance, it would be a common Instagram post some text containing the title of the film winner of the best film Oscar award and an image of the man giving the price to the winner. Traditional retrieval system don’t address this kind of retrieval, but social media can provide us a huge amount of data to made a system learn this complex “social” relations. We could learn them by mapping both the text and the image to a common space. Once that space contains enough samples, we will be able to retrieve images related to words in a “Instagram way”. That means, retrieve images that Instagram users tend to attach with the query words.
This “social association” between images and words is complex. It has a lot of variance, so we would need many samples (and computational power) to learn. It would be also complex to evaluate because it’s in many cases subjective. That’s why we have designed a bounded experiment (images associated with a city) where this complex relations happen, but where we can generate a groundtruth to evaluate our system. But the images will be divers, and their “social association” with the city names will be as complex as any other twitter data. For instance, we could be learning that people uploading selfies in Miami smile more than in London.