Retrieval Guided Unsupervised Multi-Domain Image to Image Translation
This work has been published in ACM MM 2020. Refer to the paper to access the full and formal article. Here I explain informally and briefly the experiments conducted and the conclusions obtained.
The code used in this work is available here.
This work builds over GMM-UNIT, a model for Multi-Domain Image to Image Translation. GMM-UNIT learns to generate images in different domains learning from unpaired data. In order words: It learns to generate an image similar to a given one but with different attributes. When learning from face images with annotated attributes (i.e. man, blond, young), it learns to generate a face image similar to an input one but with different attributes (i.e. turn this young man old; turn this woman blond).
In this paper we propose a method that improves GMM-UNIT performance by exploiting an image retrieval system that provides during training real images similar to the input one but with the desired target attributes. The hypothesis is that GMM-UNIT can benefit from those real retrieved images to generate more realistic images.

If you prefer video format, here is the video I made to present the article in (online) ACM MM 2020
Data
We use the Large-scale CelebFaces Attributes (CelebA) Dataset dataset which contains around 200k celebrity face images with 40 annotated binary attributes.

But only the following attributes are used: : hair color (black/blond/brown), gender (male/female), and age (young/old), which constitute 7 domains.
Procedure
We follow these steps:
-
Train a standard GMM-UNIT I2I translation model. This model implicitly learns to extract attribute features (encoding the image domain; i.e. man, blond, old) and content features (encoding the image content, which is the visual appearance not defined by the used attributes).
-
Train an image retrieval system able to find images with the given content and attribute features (using the feature exractors learned in step 1).
-
Train the I2I translation model with the retrieval guidance (RG-UNIT). For a given training image and target attributes, the most similar images are found by the retrieval images, and exploited for the image generation. (Importantly, the content and feature extractors are frozen in this step, to avoid damaging the retrieval performance).
Since step 1 is the standard training explained in GMM-UNIT, we skip its explanation in this blog post. Just remember that GMM-UNIT learns a content features extractor (\(E_c\)) and an attributes features extractors (\(E_a\)) which are frocen from now on, and used in the following steps.
Image Retrieval System Training
The image retrieval system is trained with a triplet loss to embed images with similar content features and attribute features nearby in a vectorial space. You can learn about triplet loss and ranking losses in general here.
The retrieval system input is a concatenation of the content features and the attribute features. To create the triplets to train our model, we exploit the GMM-UNIT I2I translation system trained in step 1, as explained in the following figure:
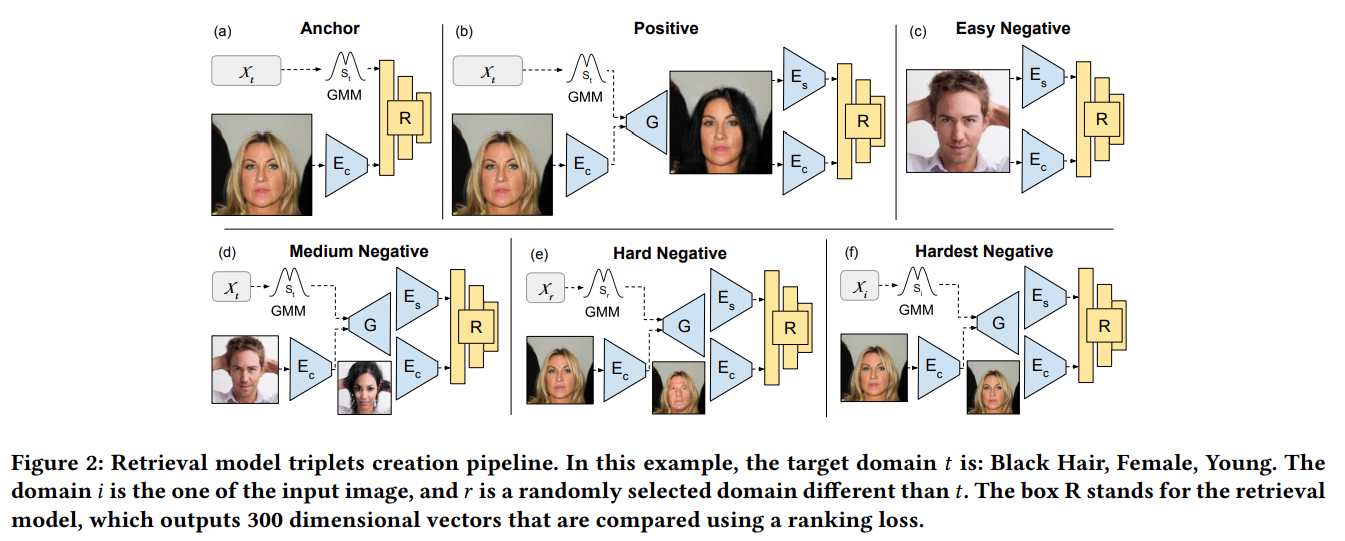
- Anchor: The content features of a given image and the desired target attributes.
- Positive: The anchor image is translated to the desired attributes. The positive sample is formed by the content features and the attributes features of the generated image.
- Easy Negative: A random real image.
- Medium Negative: A generated image with the target anchor attributes given a random image as input.
- Hard Negative: A generated image with random attributes given the anchor image as input.
- Hardest Negative: A generated image with the anchor image original attributes given the anchor image as input.
The negatives mining strategy is crucial for the training, as shown in these results:
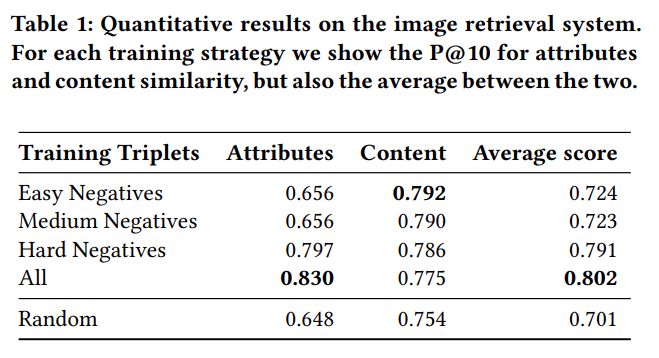
Here some results of the trained retrieval system:

Retrieval Guided I2I Translation Training
Now we have a retrieval system able to find real images with the desired content and attributes. During the I2I translation system training, we aim to teach a model to generate images similar to an input one in content but with the desired attributes. The retrieval guidance provides the generator with real images similar to the input one in content but with the desired attributes, and we aim that those images are useful to teach the generator to create more realistic images.
This is the training pipeline of the proposed retrieval guided image to image model:
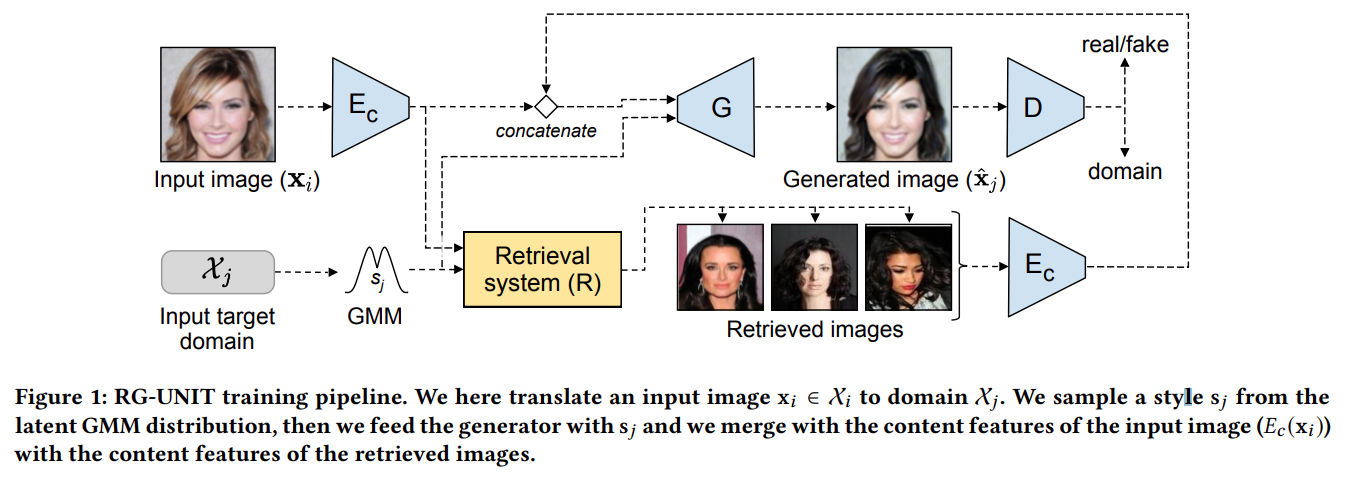
The idea is simple: The retrieval system returns the images it founds and their content features are concatenated with the generator input. Importantly, the content and attributes feature extractors (\(E_c\), \(E_a\)) are frozen during this training. Else, the retrieval system would fail.
Quantitative Results
Quantitative results show that the retrieval guidance boosts GMM-UNIT performance in different image quality metrics:
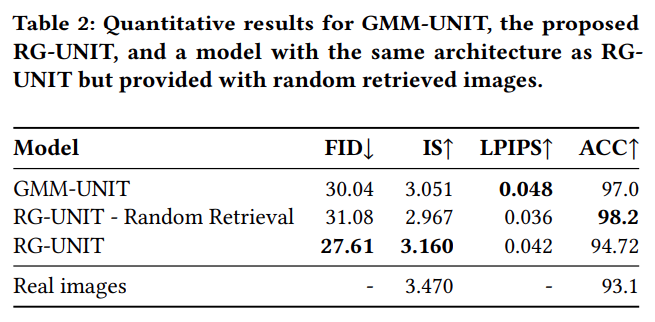
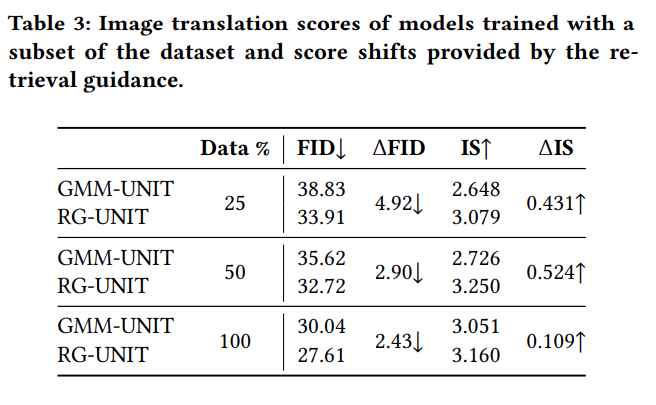
An important and nice feature of the retrieval guidance, is that its retrieval set is not limited to annotated images. Therefore, the retrieval guidance can benefit from additional unnanotated data, which can possibly boost even more the performance. To simulate that scenario, we train the RG-UNIT with a subset of the dataset, but include the whole dataset as the retrieval set. That results in a bigger performance improvement:
Qualitative Results
Here we show qualitative results of the proposed Retrieval Guided Unsupervised Multi-Domain Image to Image Translation method.



This work has been published in ACM MM 2020. Refer to the paper to access the full and formal article.