Exploring Hate Speech Detection in Multimodal Publications
This work has been accepted for publication in WACV 2020. Refer to the paper to access the full and formal article. Here I explain informally and briefly the experiments conducted and the conclusions obtained.
What is Multimodal Hate Speech?
Hate speech is defined as (Facebook, 2016, Twitter, 2016):
“Direct and serious attacks on any protected category of people based on their race, ethnicity, national origin, religion, sex, gender, sexual orientation, disability or disease.”
Modern social media content usually include images and text. Some of these multimodal publications are only hate speech because of the combination of the text with a certain image. That is because the presence of offensive terms does not itself signify hate speech, and the presence of hate speech is often determined by the context of a publication. Moreover, users authoring hate speech tend to intentionally construct publications where the text is not enough to determine they are hate speech. This happens especially in Twitter, where multimodal tweets are formed by an image and a short text, which in many cases is not enough to judge them. Following, some paradigmatic examples were a joint interpretation of the image and the text is required to identify that they are hate speech.

There are several works in automatic Hate Speech detection, but all of them use only textual data. A recent survey of them can be found here). With this project we pretend to extend that work to a multi-modal (text and image) analysis. As the Hate Speech detection in multi-modal publications problem has not been adressed yet, there are not available datasets. That’s why we created and made available MMHS150K.
Recently two related papers, also working on hate speech detection on images and text appeared. In this work Facebook uses user-reported data from their Social Network to conduct a similar research (though they probably won’t publish the dataset). In this other work they target the similar task of detecting hate speech MEMES containing visual and textual information.
The MMHS150K Dataset
Existing hate speech datasets contain only textual data. We create a new manually annotated multimodal hate speech dataset formed by 150,000 tweets, each one of them containing text and an image. We call the dataset MMHS150K.
Tweets Gathering
We used the Twitter API to gather real-time tweets from September 2018 until February 2019, selecting the ones containing any of the 51 Hatebase terms that are more common in hate speech tweets, as studied in this work. We filtered out retweets, tweets containing less than three words and tweets containing porn related terms. From that selection, we kept the ones that included images and downloaded them. Twitter applies hate speech filters and other kinds of content control based on its policy, although the supervision is based on users’ reports. Therefore, as we are gathering tweets from real-time posting, the content we get has not yet passed any filter.
Annotation
We annotate the gathered tweets using the crowdsourcing platform Amazon Mechanical Turk. There, we give the workers the definition of hate speech and show some examples to make the task clearer. We then show the tweet text and image and we ask them to classify it in one of 6 categories: No attacks to any community, racist, sexist, homophobic, religion based attacks or attacks to other communities. Each one of the 150,000 tweets is labeled by 3 different workers to palliate discrepancies among workers. The raw annotations got from AMT ara available for download with the dataset.
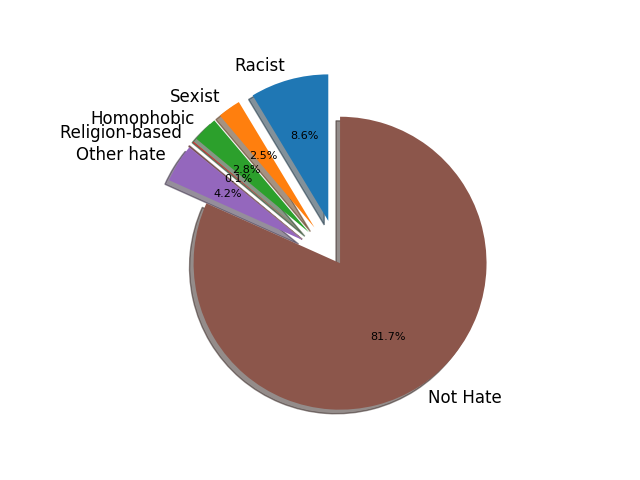
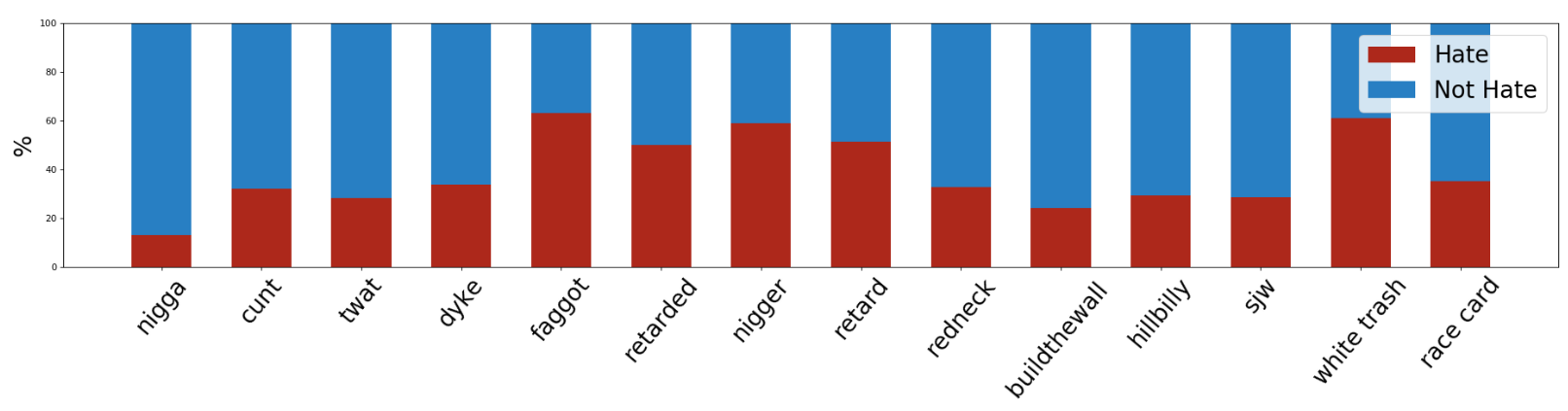
We received a lot of valuable feedback from the annotators. Most of them had understood the task correctly, but they were worried because of its subjectivity. This is indeed a subjective task, highly dependent on the annotator convictions and sensitivity. However, we expect to get cleaner annotations the more strong the attack is, which are the publications we are more interested on detecting. Below, the percentage of tweets labeled in each one of the classes, and the percentage of hate and not hate tweets for the most frequent keywords.
Dataset Contents

img_resized/
Images resized such that their shortest size is 500 pixels
File name is tweet ID
MMHS150K_GT.json
Python dict with an entry per tweet, where key is the tweet ID and fields are:
tweet_url
labels: array with 3 numeric labels [0-5] indicating the label by each one of the three AMT annotators
0 - NotHate, 1 - Racist, 2 - Sexist, 3 - Homophobe, 4 - Religion, 5 - OtherHate
img_url
tweet_text
labels_str: array with the 3 labels strings
img_txt/
Text extracted from the images using OCR.
hatespeech_keywords.txt
Contains the keyworkds that were used to gather the tweets.
splits/train_ids.txt
splits/val_ids.txt
splits/test_ids.txt
Contain the tweets IDs used in the 3 splits
Download MMHS150K (6 GB) CVC (Lab) | Google Drive | Mega
Methodology
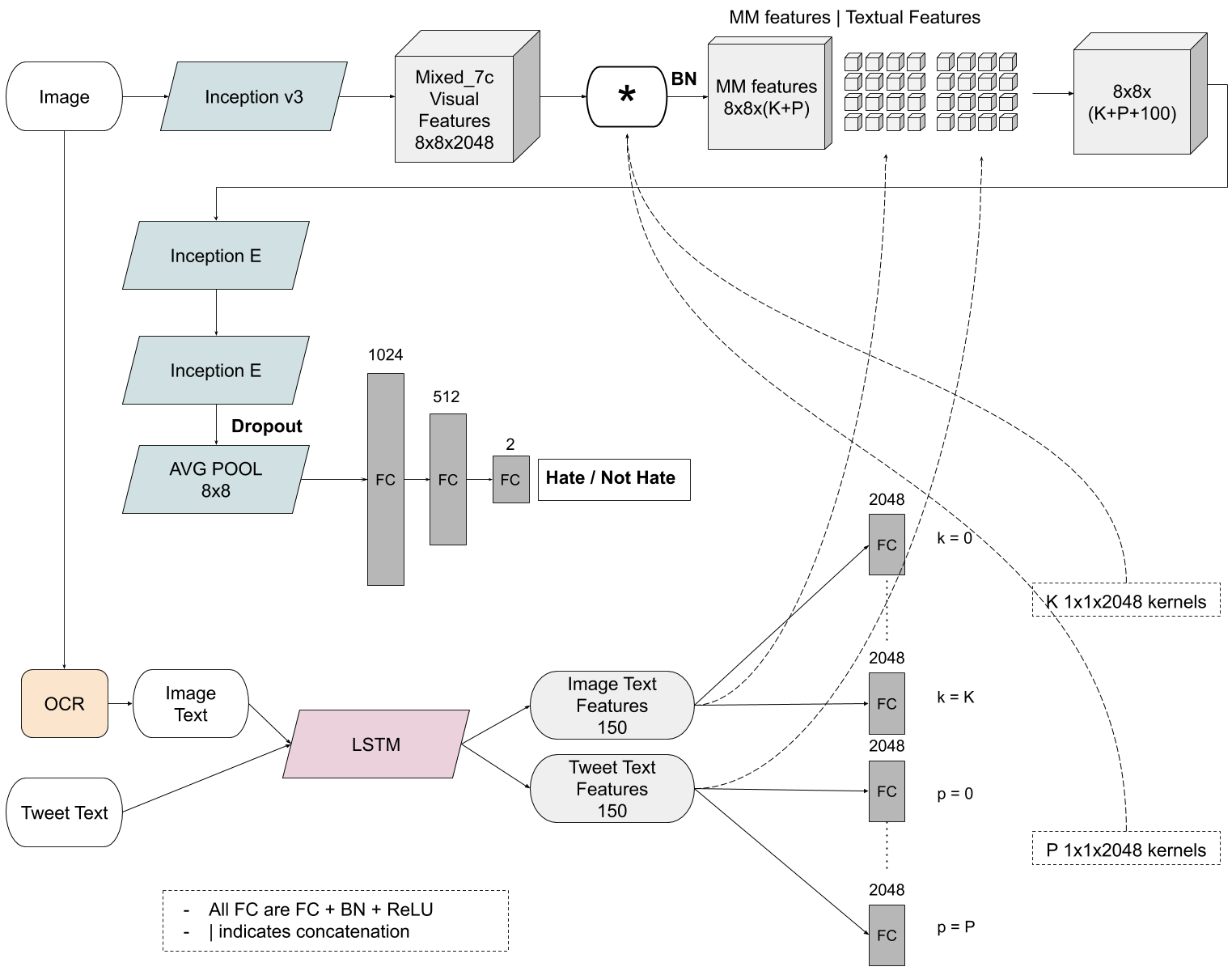
The objectives of this work are to introduce the task of hate speech detection on multimodal publications, to create and open a dataset for that task, and to explore the performance of state of the art multimodal machine learning models in the task. As a baseline, we train an LSTM for hate speech detection using only the tweets text. We aim to train multimodal models that exploit also the visual information to outperform the LSTM by succesfully detecting those hate speech instances where the interpretation of the visual information is needed.
We also extract the text appearing in the images if it exists, which consitutes another input to our models.
We use an Inception v3 architecture for the image feature extraction, and then propose two different multimodal models to fuse image and textual features, process them jointly and make a decision. The first one, which we call Feature Concatenation Model (FCM) is a simple MLP that concatenates the image representation extracted by the CNN and the textual features of both the tweet text and the image text extracted by the LSTM. This simple strategy has given competitive results in many multimodal task, and it’s hardly being outperformed by more complex approaches.
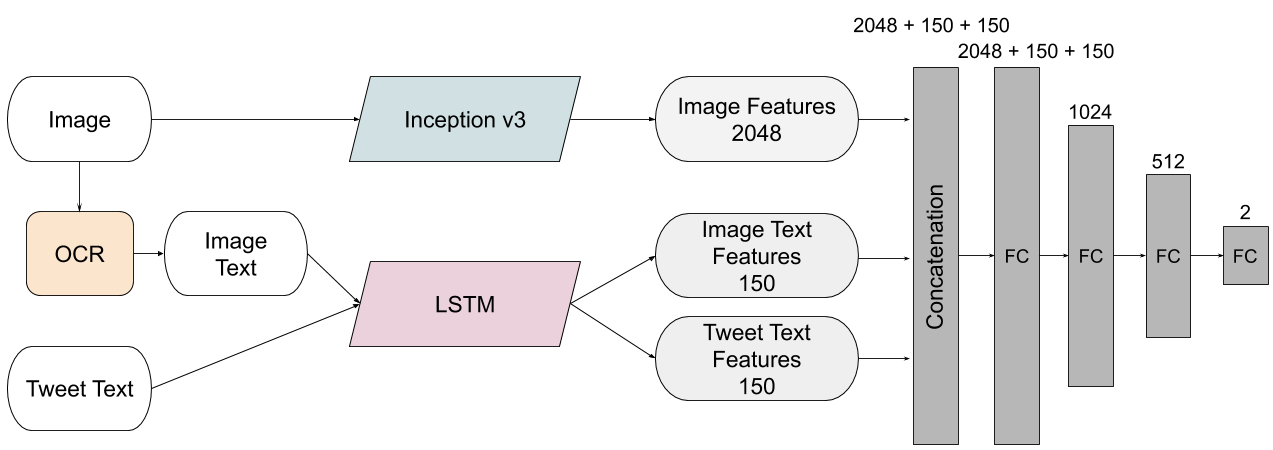
We propose a second multimodal model called Textual Kernels Model (TKM), inspired by this VQA work. The idea is to learn kernels dependent on the textual representations and convolve them with the visual representations in the CNN. The intuition is that we can look for different patterns in the image depending on the associated text.
Results
The table below shows the F-score, the Area Under the ROC Curve (AUC) and the mean accuracy (ACC) of the proposed models when different inputs are available. TT refers to the tweet text, IT to the image text and I to the image. It also shows results for the LSTM, for the Davison method trained with MMHS150K, and for random scores.
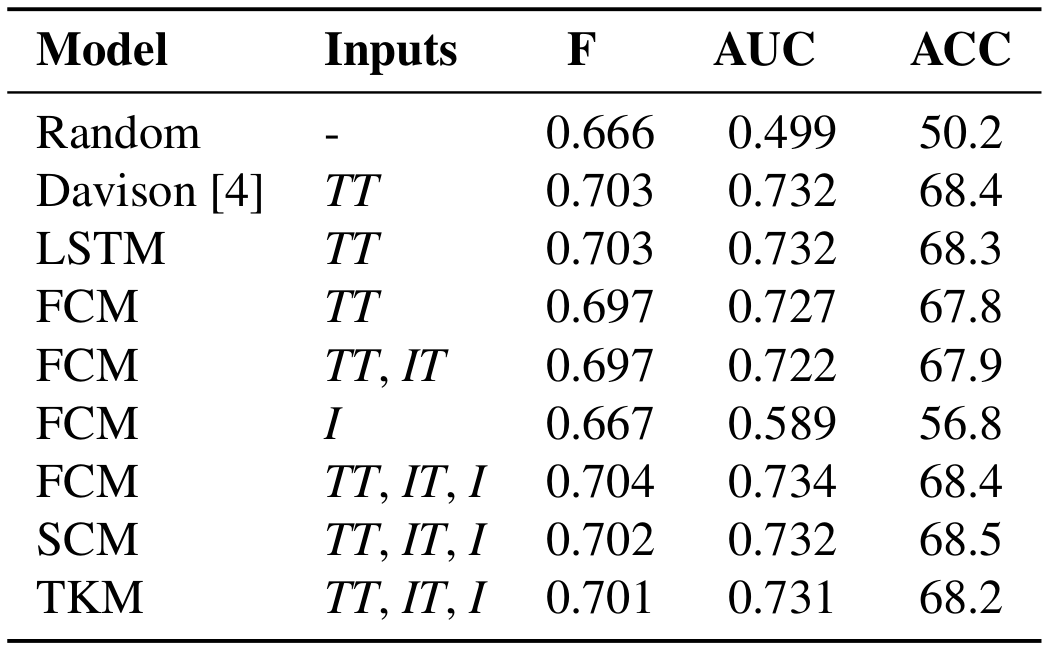
First, notice that given the subjectivity of the task and the discrepancies between annotators, getting optimal scores in the evaluation metrics is virtually impossible. However, a system with relatively low metric scores can still be very useful for hate speech detection in a real application: it will fire on publications for which most annotators agree they are hate, which are often the stronger attacks.
The FCM trained only with images gets decent results, considering that in many publications the images might not give any useful information for the task. The following figure shows some representative examples of the top hate and not hate scored images of this model. Many hate tweets are accompanied by demeaning nudity images, being sexist or homophobic. Other racist tweets are accompanied by images caricaturing black people. Finally, MEMES are also typically used in hate speech publications. The top scored images for not hate are portraits of people belonging to minorities. This is due to the use of slur inside these communities without an offensive intention, such as the word nigga inside the afroamerican community or the word dyke inside the lesbian community. These results show that images can be effectively used to discriminate between offensive and non-offensive uses of those words.

Despite the model trained only with images proves that they are useful for hate speech detection, the proposed multimodal models are not able to improve the detection compared to the textual models. Besides the different architectures, we have tried different training strategies, such as initializing the CNN weights with a model already trained solely with MMHS150K images or using dropout to force the multimodal models to use the visual information. Eventually, though, these models end up using almost only the text input for the prediction and producing very similar results to those of the textual models.
Conclusions
Given that most of the content in Social Media nowadaysis multimodal, we truly believe on the importance of pushing forward this research. The main challenges of this task are:
-
Noisy data. A major challenge of this task is the discrepancy between annotations due to subjective judgement.
-
Complexity and diversity of multimodal relations. Hate speech multimodal publications employ a lot of background knowledge which makes the relations between visual and textual elements they use very complex and diverse, and therefore difficult to learn by a neural network.
-
Small set of multimodal examples. Although we have collected a bigd ataset of 150K tweets, the subset of multimodal hate here is still too small to learn the complex multimodal relations needed to identify multimodal hate.
The code used in this work will be available soon here.