FCN for Face and Hair Segmentation
Following a similar approach than the one used to train the Text Detection FCN I trained the same FCN model for Face and Hair pixel level segmentation. As in the TextFCN, the model used is the fcn8s-atonce model by Long and Shelhamer, in this case adapted to detect 3 classes: Face, Hair and Background.

Siyang Qin, from the University of California, published a similar approach in ICME 2017, which includes a segmentation refinement and a lighter FCN, and probably produces better results than the model provided here. However, they don’t provide code nor a trained model.
Data
The model has been trained using the Part Labels Database. It contains 2927 images of faces of famous people with pixel-level labelings into Hair/Skin/Background labels. Images size is 250x250 pixels.


Training and data augmentation
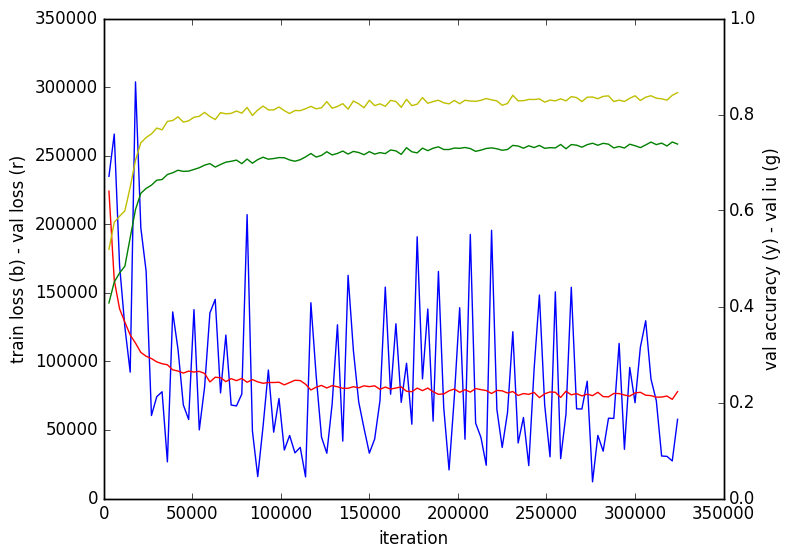
The FCN has been trained using Caffe for 300k iterations with a batch size of 1. A fixed learning rate of 1e-12 has been used, with a momentum of 0.99 and a weight decay of 0.005.
The learning rate is so low because the loss in not normalized over pixels.
The size of the training images is set to 512x512 to better fit the receptive field of the FCN. An aggressive data augmentation is used, and I’ve found it to be it necessary in this case to overcome the limited amount of data and its low variance. Specifically, I found that in all the training images the faces are centered and have a similar size respect to the image. That made a model trained without data augmentation fail detecting non-centered faces or smaller faces.
Initially images are resized to 600x600. Then mirroring is applied with a probability of 0.5. Then, a random zero padding between 0 and 250 is added with a probability of 0.5. Then the resulting images are rescaled with a random scaling factor from 1 to 1.4. Finally, a random crop of 512x512 is taken from that image. The data augmentation is performed online using a PyCaffe data layer, and the code is self-explanatory.
Usage Tips
The size of the original images are small (250x250 pixels), but to train the net I upscale them (512x512) to better fit the receptive field of the FCN. That makes the net learn patterns on smooth images since they have been upscaled. I found that in test phase, the model also works better with upscaled images. So, even if your test images are of 512x512, the predictions will be better if you first downscale them to 250x250 and the upscale them back to 512x512.
Results
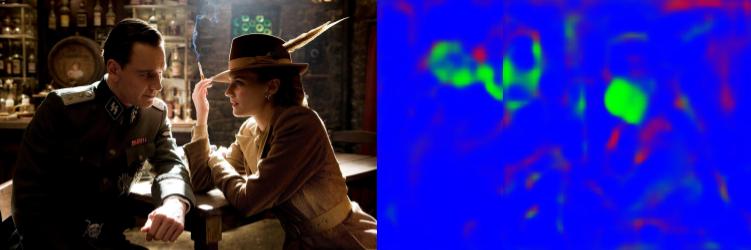
Results on Face Parts Labels test set: The model works quite well on the Parts Labels test set, where faces are centered and well lighted.

Results on other images: Despite being far from perfect, results are quite nice in other images, even if there are many faces per images.


Failure cases: The model fails under bad lighting conditions, both if the faces are dark or contain reflections.