Data Augmentation Benchmarking on CNN Training
I have always used online data augmentation (using caffe python layers) when training CNN’s. But I’ve never checked if it really helps to achieve a better accuracy in the trained models. I observed that it prevents overfitting. But does data augmentation help to train models that generalize better? How does it influence the training process? Should we use it? To answer these questions and decide which data augmentation techniques use, I did this benchmarking of different data augmentation techniques to train a CNN for image classification.
Data augmentation techniques
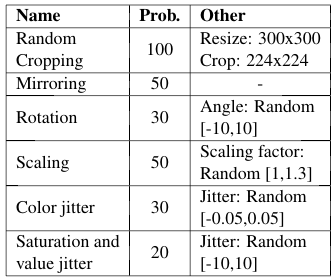
- Random Cropping The input image for the CNN is a random crop of the original training image. To prevent the crop to be a very small part of the image, it can be preceded by an image resize.
- Mirroring An horizontal flip of the image is performed with a certain probability.
- Rotation The image is rotated with a certain probability. The rotation angle is random and bounded.
- Scaling The input image is rescaled by a certain factor with a given probability. It only makes sense to use it together with random cropping, so the crops are of areas of the image of different sizes.
- Color jitter One of the color channels of the image is modified adding or subtracting a random and bounded value.
- Saturation and Value jitter The image is transformed to the HSV color space and its Saturation and Value values are modified adding or subtracting a bounded and random value.
In the experiments I first train a model without any data augmentation. That is resizing the training images to the size of the CNN input layer (224x224). Then I train a model for each one of the proposed data augmentations techniques. For all those models, random cropping will also be used. I also train a model using all the proposed techniques at the same time.

Experiments
To benchmark the different data augmentation techniques I use a CaffeNet CNN, which is a model very similar to the popular AlexNet. I initialize the weights with the ImageNet trained model and fine-tune them with a fixed learning rate of 0.001, which is boosted x10 in the last fully connected layer and a batch size of 100. I used Caffe and performed online data augmentation using a custom python data layer.
The code for the model training implementing the data augmentations techniques can be found here.
I trained the CNN for classification on the 102 Category Flower Dataset. Its formed by 8,189 images of 102 different flowers classes, split in 6,109 training images, 1020 validation images and 1020 test images. The images have diverse sizes.
Results
Next figures show the training and validation accuracy during the training of the CNN using the different data augmentation techniques.
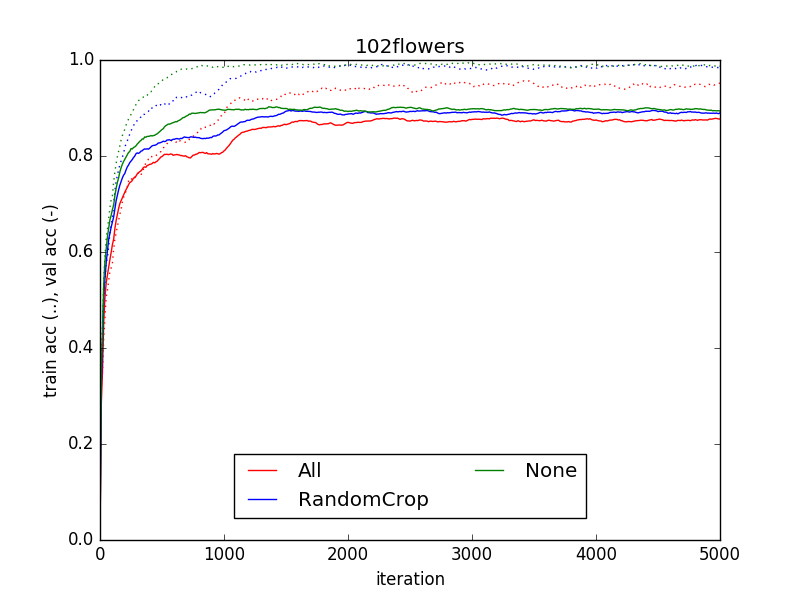
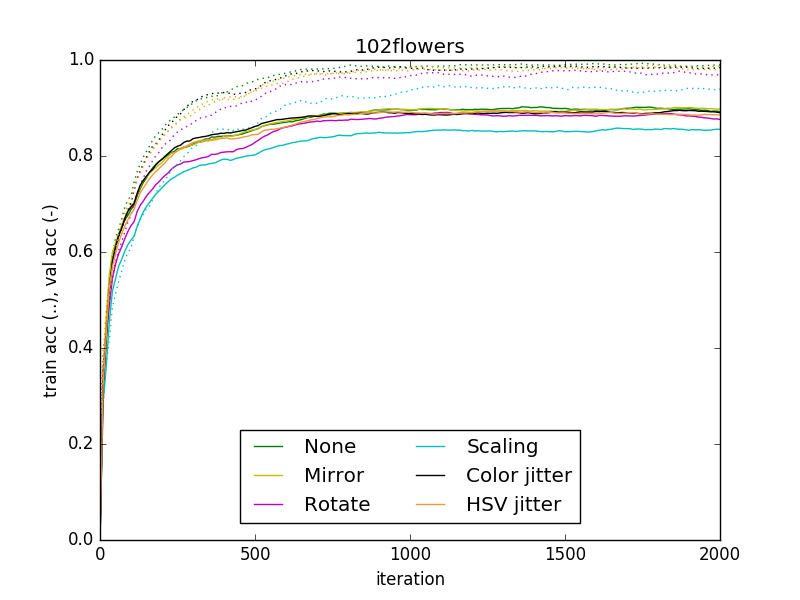
The results show that the data augmentation techniques used do not help to improve the validation accuracy of the model, so they don’t help to train a model that generalizes better. They make the model to converge slower and, when the data augmentation is aggressive, it damages the model final performance. Comparing training vs validation accuracies we see that data augmentation prevents overfitting. That’s natural because we are increasing the size of our training set, but in this case does not lead to an increase in the generalization power of the model.
Conclusions
The reason why data augmentation does not help is probably that the patterns learnt by the CNN itself when no data augmentation is used are robust to the variance that we introduce with the data augmentation
Ex. If we train with a dataset of cats and dogs all looking to the left, the net will be able to identify cats and dogs when they are looking to the right.
The reason why the results with data augmentation are worse and not equal, is probably that when we introduce artificial variations to the training data we generate images that wouldn’t exist in the real life (or that have a low probability to exist). That confuses the net by forcing it to learn patterns from an image that it won’t find in the validation set, or from a rare image in the validation set.
Ex. With the same cats and dog dataset we introduce rotation as data augmentation. But people don’t take pictures rotated. So that extra intra-class variance increases the complexity of the problem, which might lead to worst results.
I’ve checked the results of this experiment in other datasets and in other tasks and got the similar results and the same conclusions.
So from now I won’t use these data augmentation techniques. I might still use random cropping with non-aggressive parameters because is much more efficient to crop than to resize images and also because that avoids deforming the image.
This work by Google studies how regularizers (such as data augmentation) impact the CNN training process and its generalization error. Check it, it’s interesting!