Barcelona DeepDream
Models trained with #Barcelona Instagram data
I research in methods to learn visual features from paired visual and textual data in a self-supervised way. A natural source of this multimodal data is the Web and the social media networks. As an application of my research, I trained models to learn relations between words and images from Instagram publications related to #Barcelona. Using that technology I did an analysis of what relations between words and images do tourists vs locals establish, which was published in the MULA ECCV 2018 workshop, and is available here.
In this post I use the Google DeepDream algorithm on those models. DeepDream magnifies the visual features that a CNN detects on an image, producing images where the recognized patterns are amplified. Applying it to models trained with #Barcelona Instagram data, we can generate images where the visual features that are more strongly related to most mentioned concepts are amplified, which shows us in a single canvas the most popular visual features and concepts of #Barcelona.
The DeepDream algorithm
The DeepDream algorithm was presented by Google in this post of its AI Blog in 2015. It magnifies the patterns that a given layer recognizes in an input image, and then generates a new image where those patterns are amplified. The basic idea, as it is explained in their blog, is asking the network: “Whatever you see there, I want more of it”. As an example, imagine that we have a CNN trained to recognize only car wheels. When we input an image and use the DeepDream algorithm to amplify what the network sees, it will create an image where any circular shape in the input image has been “converted into” a car wheel (actually, into how the CNN thinks a car wheel looks like).
We can select any layer and ask the CNN to enhance what it sees. Lower layers will produce lower level patterns, since they are sensible to basic features, but higher layers will produce more sophisticated patterns or whole objects. Applying this algorithm iteratively (to its own output) will result in images where the detected patterns have been more amplified. If we add some zooming and scaling to the iteration process, we can generate images that look pretty good.
I recommend reading their blog post. They also provide a IPython notebook based on Caffe with a DeepDream implementation. The code I have used, adapted from that notebook, is available here.
Results
To understand what the algorithm is doing, let’s inspect what it does in the first iterations.


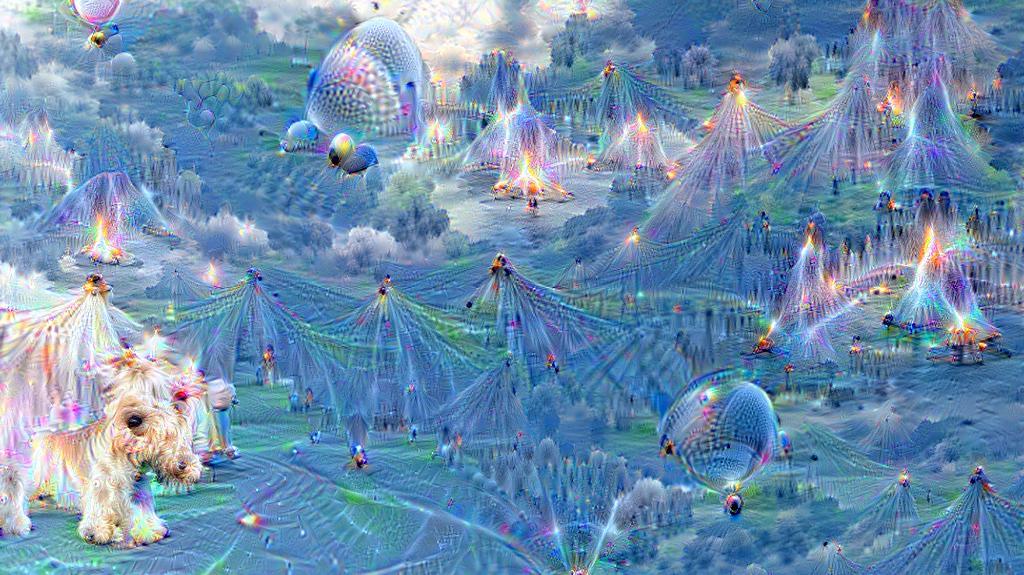
Hallucinating a city
Can you recognize anything in the above results?


Let’s continue iterating:
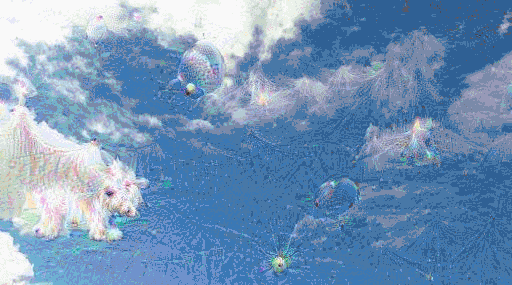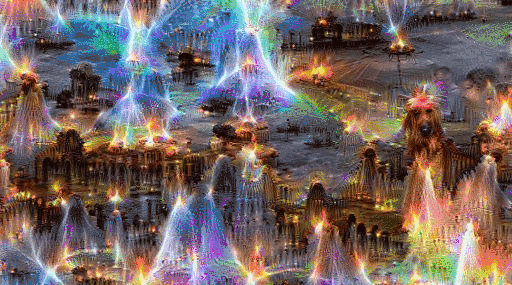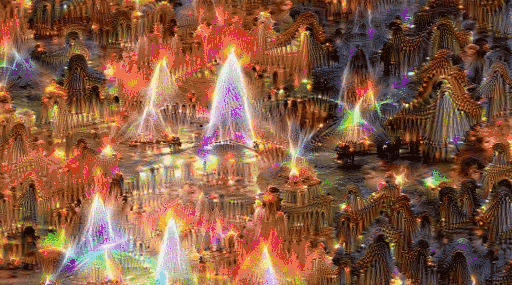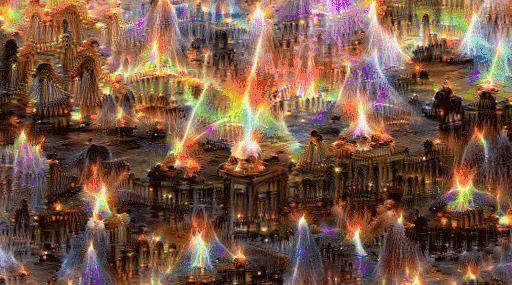

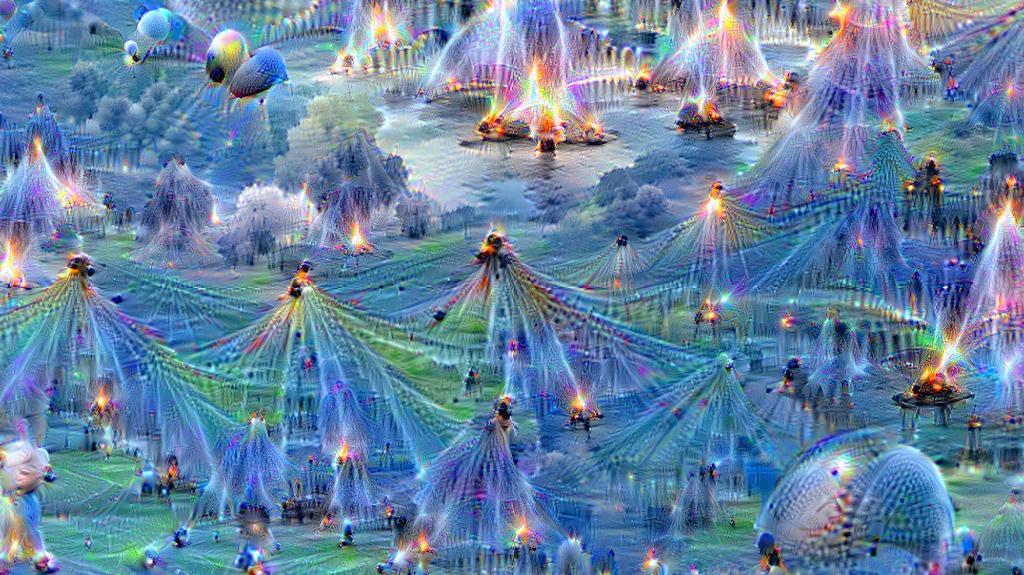
Interesting right? Looks like a city made of deformed Barcelona top tourist attractions with some random dogs (inherited from the ImageNet pretraining) in it.
It’s even more hallucinatory seeing the iterative process in the opposite direction:

Using random noise
We don’t even need to use an input image. We can use random noise as the starting point, and ask the CNN to amplify what it sees on it.




Guided Hallucinations
Instead of asking the net to amplify what a layer recognizes on an image, we can guide the hallucinations. We do that by using a guide image and asking the net to amplify in the input image what it sees in that guide image.
Hamburguer-Guided Hallucination
Using this technique, we can ask the CNN to amplify the hamburger recognitions. -Actually, since we have trained the CNN to embed images in a semantic space, we will are asking to amplify food recognitions-.



Gaudí-Guided Hallucination
Let’s see now what the CNN hallucinates when we ask it to amplify Gaudi related stuff, using as the guide image his dragon statue.



Sunset-Guided Hallucination



Amplifying different layers
Amplifying different layers and using different input images result in really cool images.
The Barcelona Islands




The Football Club Barcelona Detector

The spacecraft control center


Bigger images
The size of the generated images is only limited by your GPU memory. With a Titan X 12GB I’ve been able to generate 3500x1800 images, as the one shown below. This DeepDream implementation allows to generate bigger images and to use multiple GPU’s.
